Semantic Robot Vision Challenge
University of Maryland Team
The Terrapins
| Home | Approach | Hardware | Software | Media |
Semantic Robot Vision Challenge University of Maryland Team The Terrapins |
|||||||||
|
|||||||||
Approach
2007 |
Navigation |
||
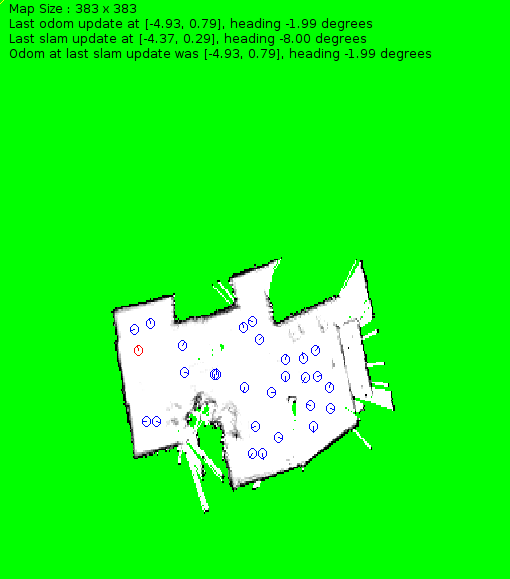
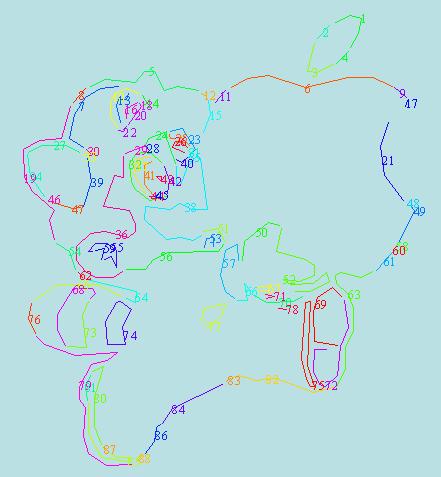
We have a Simultaneous Localization and Mapping (SLAM) module that creates a 2D occupancy grid of the environment using laser range data. The laser sensor is mounted on a tilt unit, and takes a few (5) sweeps to build a rough depth map. During the first few minutes, we explore the room and build a map of it. Then we place waypoints on the map . These waypoints are minimal set of poses to cover all areas potentially containing objects. During the remainder of the time in the room the robot visits these points and takes images there. The image below shows the map built during a test run.
The green area is unexplored area, the white area is explored unoccupied area and the black pixels correspond to the obstacles. The blue circles indicate the pose of the waypoints, while the red circle is the pose of the robot.
|
||
Object
Recognition |
||||||||
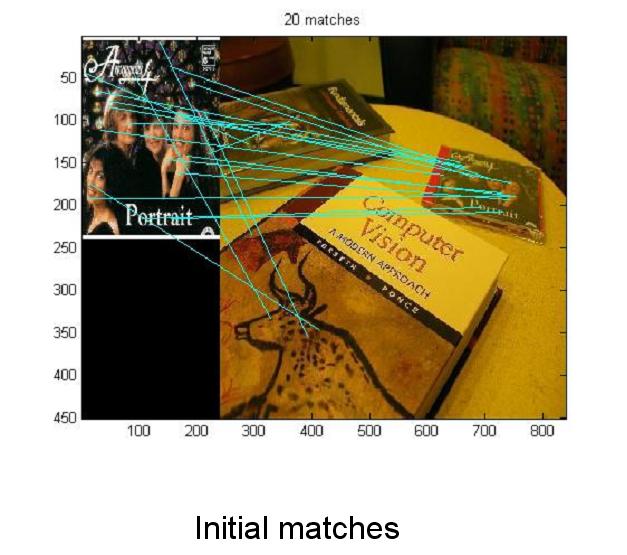
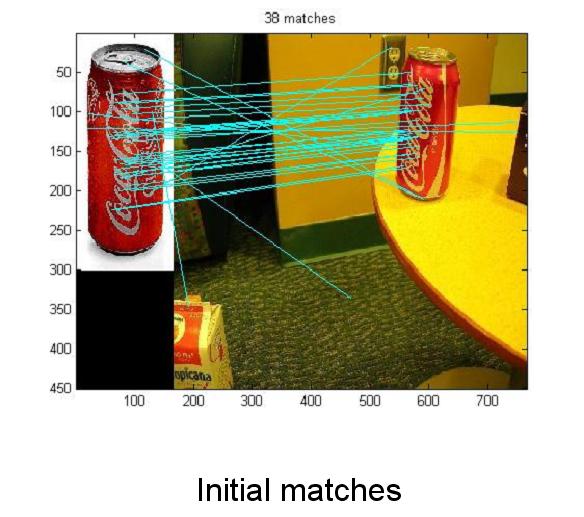
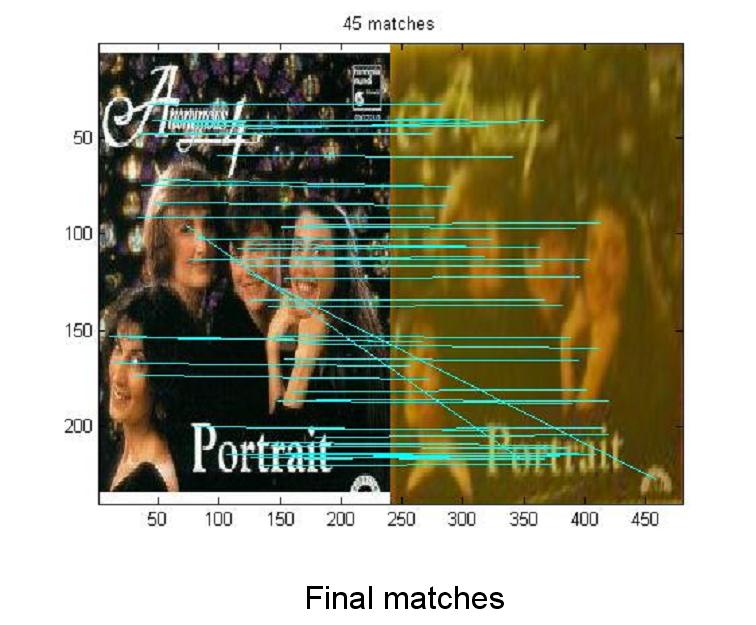
We have two strategies for object recognition; a feature based and a shape based. The feature based approach is used for proper nouns (specific objects, e.g. Coca-Cola can, Tide detergent etc), The shape based approach is used for general nouns (e.g. teddy bear, apple etc.). Feature based Method
More examples with the bounding box around segmented objects (images from the competition)
Shape Matching Segmentation The internet images are segmented on the basis of color using a modified normalized graph cut. To segment the room images we used three cameras. We precompute the homography of the ground plane between pairs of cameras. Differences between the rectified images provide the boundaries (or better occlusions) of the objects standing on the ground plane. Using simple morphological operations we segment the objects. Estimation of homography
Object Description Objects are described by histograms of local shape words. As shape words we used the so called Triple Adjacent Segments which are three neightboring line segments. The set of our shape words (the so called codebook) has been computed in advance using a few standard object recognition databases. Classifiers are build from the histograms of shape words using support vector machines.
Example
More details about our approach can be found in our paper, "Object Detection Using a Shape Codebook", X. Yu, L. Yi, C. Fermüller, D. Doermann, BMVC 2007. |
||||||||
| Home • Approach • Hardware • Software • Media | |||
| Last updated on : November 2007 | |||