
The bio-inspired, asynchronous event-based dynamic vision sensor records temporal changes in the luminance of the scene at high temporal resolution. Since events are only triggered at significant luminance changes, most events occur at object boundaries. This paper presents an approach to learn the location of contours and their border ownership using Structured Random Forests on event-based features that encode motion, timing, texture, and spatial orientations. The classifier integrates elegantly information over time by utilizing the classification results previously computed. Finally, the contour detection and boundary assignment are demonstrated in a layer-segmentation of the scene.
The DVS [Lich_08] asynchronously records address-events corresponding to scene reflectance changes, with a maximum temporal resolution of 15 microseconds, and 128 x 128 spatial resolution. This sensor fires an event every time the log intensity changes by a fixed amount at a position (x, y). An event ev(x, y, t, p) encodes position and time information, along with the polarity p of the event, that is, +1 or -1 depending on whether the log of the intensity increases or decreases by a global threshold.
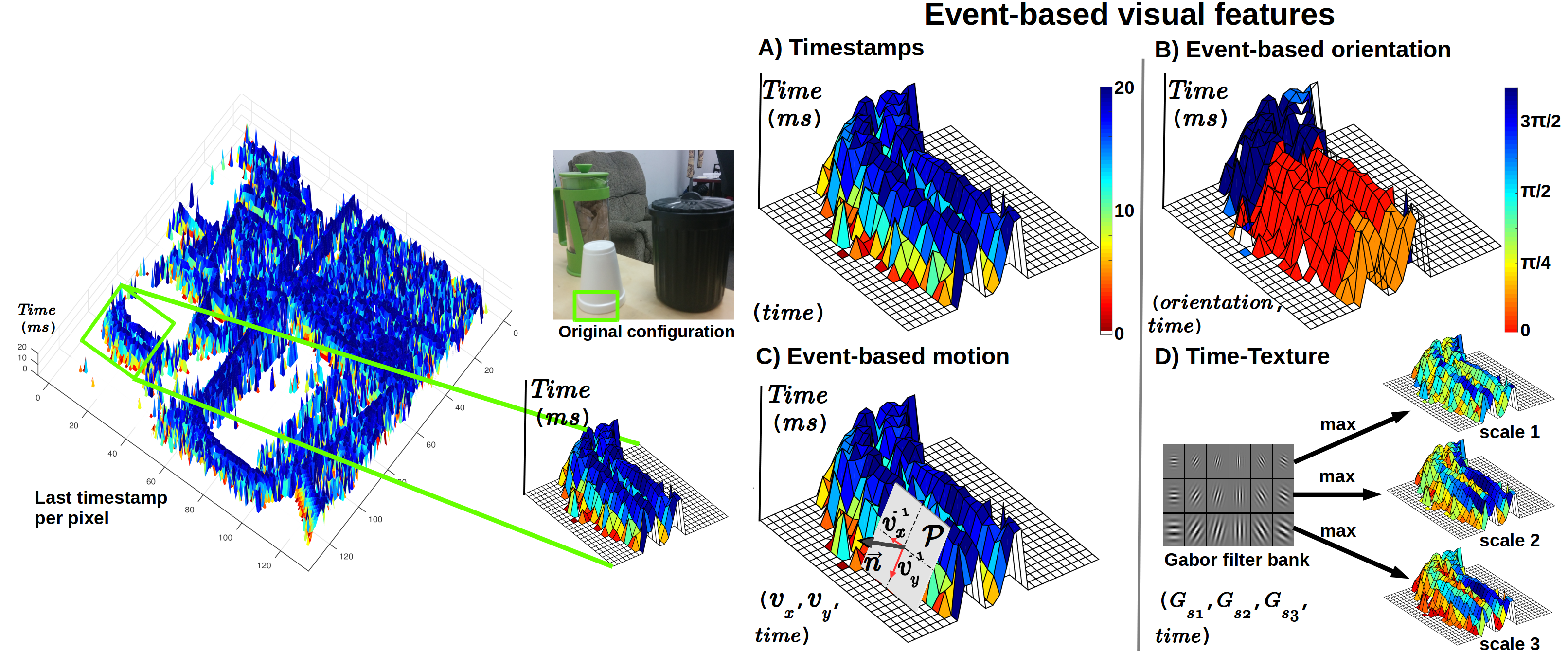
Due to the nature of the DVS, visual frame-based features cannot be extracted. We have selected our own event-based features on the basis of how their evolution in time could help us detecting occlusion boundaries.
Event-based Orientation. As done in [Kan_76], we use the convexity of edges, which is encoded by the edge orientation as a cue for border ownership. The intuition is that concave edges often belong to foreground objects. We consider spatio-temporal neighborhoods of 11 x 11 pixels and 20ms, and 8 orientations (from 0 to pi). A normalized Histogram of Orientations with 8 bins is computed for patches of 15 x 15 pixels.
Event temporal information. Timestamps provide information for tracking contours [Del_08], defining a surface that encodes locally the direction and speed of image motion. The changes of this time-surface also encode information about occlusions boundaries. We collect the following features: the number of events accumulated for different time intervals, the first and last times tamps of the events at every pixel, and the series of timestamps for all the events per location.
Event-based Motion Estimation. Image motion encodes relative depth information useful for assigning border ownership. The idea is formulated in the so-called motion parallax constraint, used in previous works [Ste_09], i.e. objects that are close to the camera move faster in the image than objects farther away.
Event-based time texture. The aim in this case is to separate occlusion edges from texture edges. First, texture edges are surrounded by nearby edges with comparable contrasts making them not very salient [Ren_06]. Second, long smooth boundaries with strong texture gradients are more likely to occur at occlusions. Instead of intensity texture gradients as used on images, we use a map of the timestamps of the last event triggered at every pixel.
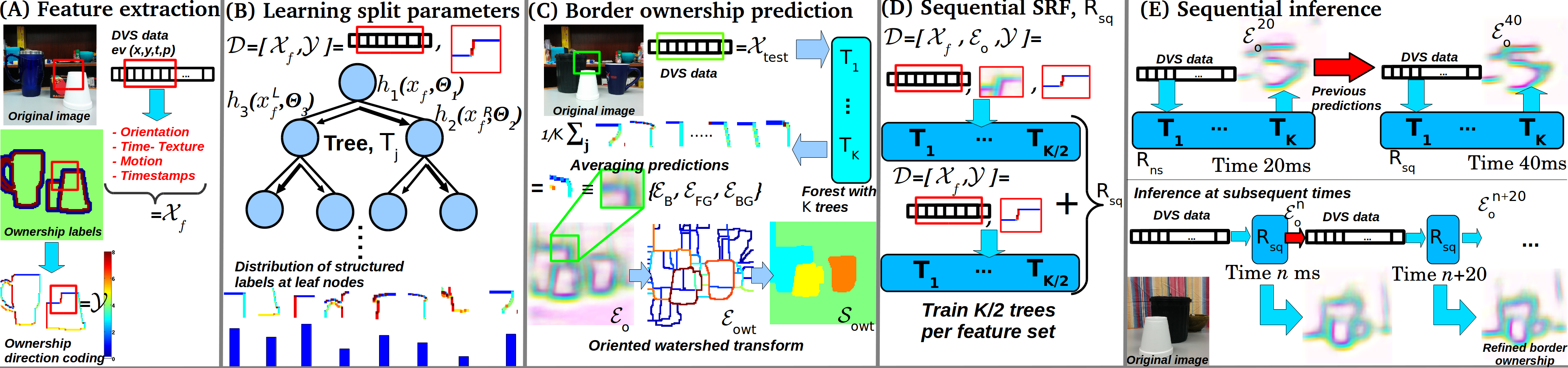
The SRF (see [Dol_13][Kon_11]) is trained for border ownership assignment using event-based features from random (16 x 16) patches. (A) Given the training data D, we learn an optimal splitting threshold Θi, associated with a binary split function hi at every split node. (B) The leaves at each tree Tj encode a distribution of the ownership orientation which we use during inference. Averaging the responses over all K trees produces the final boundary and ownership prediction: EO= {EB, EFG, EBG}. We then obtain Eowt by applying a watershed transformation over EB to construct an initial segmentation Sowt (C).
For the refinement and event based segmentation, we augment in (D-E) the event-based features with the features with the predictions computed for the previous time interval.
The original non-sequential SRF Rns creates predictions EOn, which are used with the features for the next time (n+1) as input to the sequential SRF Rsq. Finally, for the refined segmentation: 1) initial segmentation Sowt estimated form the predictions EO of the SRF; 2) segments are refined by enforcing motion coherence between them.
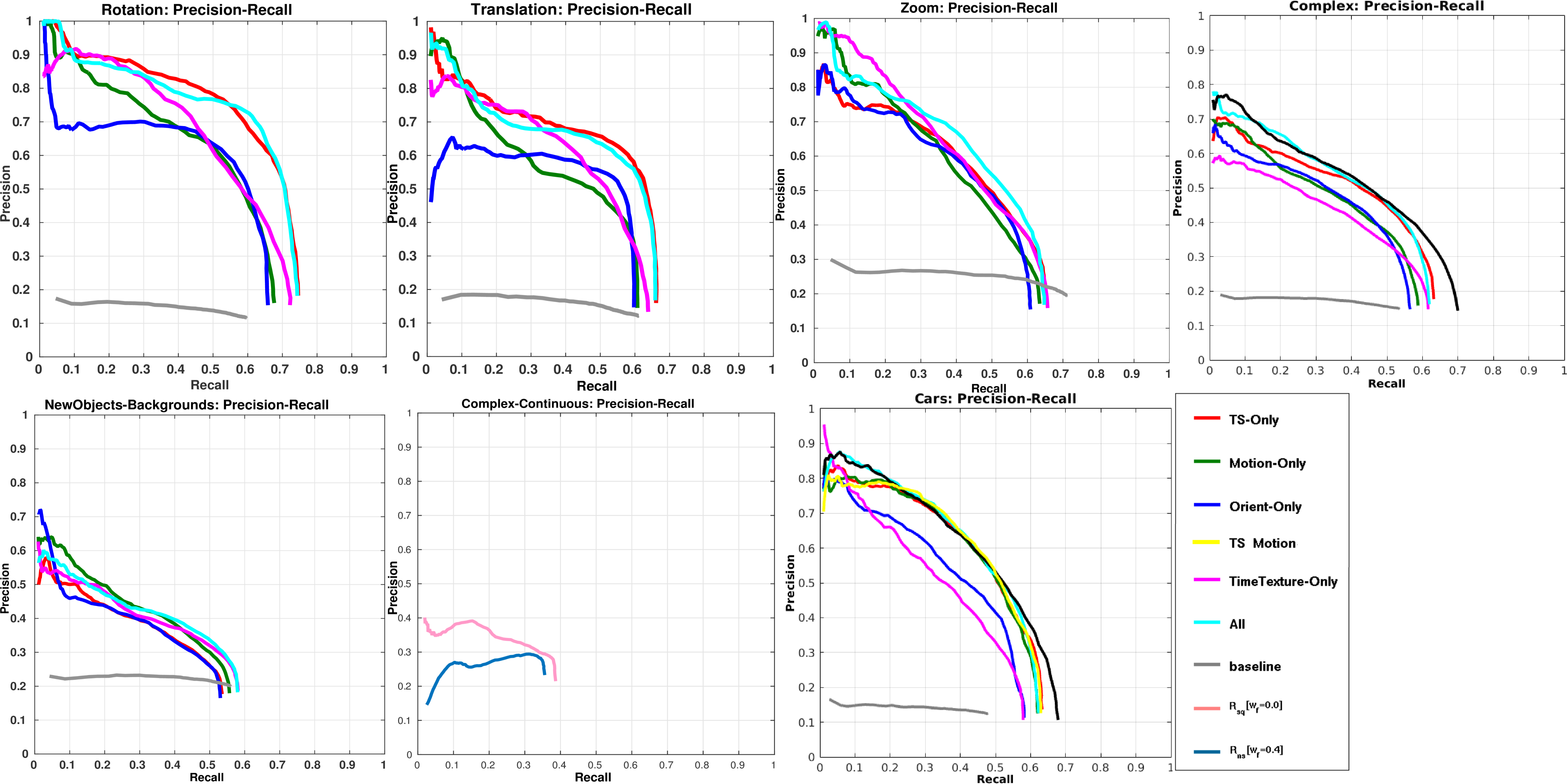
Following, some results and the PR curves for the F2 metric explained in the paper:

If you use any of our code or dataset files, please cite our paper as
F. Barranco, C. L. Teo, C. Fermuller, and Y. Aloimonos. "Contour Detection and Characterization for Asynchronous Event Sensors." In Proceedings of the IEEE International Conference on Computer Vision, pp. 486-494. 2015.
@inproceedings{barranco_contour_2015,
author = {Barranco, F. and Teo, C. L. and Fermuller, C. and Aloimonos, Y.},
title = {Contour Detection and Characterization for Asynchronous Event Sensors},
journal = {Proceedings of the IEEE International Conference on Computer Vision},
pages = {486--494},
year = {2015}
}
Questions? Please contact fbarranco "at" ugr dot es