We now consider the problem of sorting n integer keys in the range [0, M-1] that are distributed equally over a p-processor distributed memory machine. An efficient and well known stable algorithm is radix sort that decomposes each key into groups of r-bit blocks, for a suitably chosen r, and sorts the keys by sorting on each of the r-bit blocks beginning with the block containing the least significant bit positions. Here we only sketch the algorithm Counting Sort for sorting on individual blocks.
The Counting Sort algorithm sorts n integers in the range [0,
R-1] by using R counters to accumulate the number of keys equal to
i in bucket ![]() , for
, for ![]() , followed by determining
the rank of the each element. Once the rank of each element is known,
we can use our h-relation personalized communication to move each
element into the correct position; in this case
, followed by determining
the rank of the each element. Once the rank of each element is known,
we can use our h-relation personalized communication to move each
element into the correct position; in this case ![]() .
Counting Sort is a stable sorting routine, that is, if two keys
are identical, their relative order in the final sort remains the same
as their initial order.
.
Counting Sort is a stable sorting routine, that is, if two keys
are identical, their relative order in the final sort remains the same
as their initial order.
The pseudocode for our Counting Sort algorithm uses six major steps and is as follows.
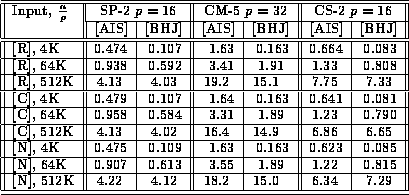
Table vi: Total execution time for radix sort on 32-bit integers (in seconds), comparing the AIS and our implementations.
Table vi presents a comparison of our radix sort with another implementation of radix sort in SPLIT-C by Alexandrov et al. [1] This other implementation, which was tuned for the Meiko CS-2, is identified the table as AIS, while our algorithm is referred to as BHJ. The input [R] is random, [C] is cyclically sorted, and [N] is a random Gaussian approximation [4]. Additional performance results are given in Figure 5 and in [4].
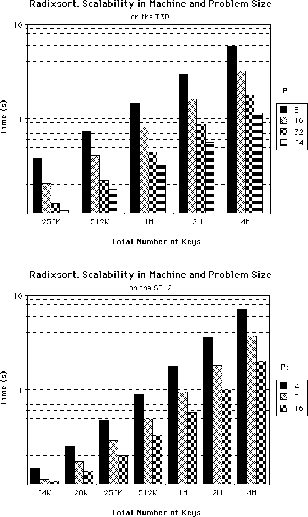
Figure 5: Scalability of radix sort with respect to machine and problem size, on
the Cray T3D and the IBM SP-2-TN