Consider the problem of sorting n elements equally distributed
amongst p processors, where we assume without loss of generality
that p divides n evenly. The idea behind sample sort is to find a
set of p - 1 splitters to partition the n input elements
into p groups indexed from 0 up to p - 1 such that every element
in the ![]() group is less than or equal to each of the elements in
the
group is less than or equal to each of the elements in
the ![]() group, for
group, for ![]() . Then the task of
sorting each of the p groups can be turned over to the
correspondingly indexed processor, after which the n elements will
be arranged in sorted order. The efficiency of this algorithm
obviously depends on how well we divide the input, and this in turn
depends on how well we choose the splitters. One way to choose
the splitters is by randomly sampling the input elements at each
processor - hence the name sample sort.
. Then the task of
sorting each of the p groups can be turned over to the
correspondingly indexed processor, after which the n elements will
be arranged in sorted order. The efficiency of this algorithm
obviously depends on how well we divide the input, and this in turn
depends on how well we choose the splitters. One way to choose
the splitters is by randomly sampling the input elements at each
processor - hence the name sample sort.
Previous versions of sample sort [16, 8, 12]
have randomly chosen s samples from the ![]() elements
at each processor, routed them to a single processor, sorted them at
that processor, and then selected every
elements
at each processor, routed them to a single processor, sorted them at
that processor, and then selected every ![]() element as a
splitter. Each processor
element as a
splitter. Each processor ![]() then performs a binary search on these
splitters for each of its input values and then uses the results
to route the values to the appropriate destination, after which local
sorting is done to complete the sorting process. The first difficulty
with this approach is the work involved in gathering and sorting the
splitters. A larger value of s results in better load
balancing, but it also increases the overhead. The second difficulty
is
that no matter how the routing is scheduled, there exist inputs that
give rise to large variations in the number of elements destined for
different processors, and this in turn results in an inefficient use
of the communication bandwidth. Moreover, such an irregular
communication scheme cannot take advantage of the regular
communication primitives proposed under the MPI standard [20].
The final difficulty with the original approach is that duplicate values
are accommodated by tagging each item with some unique value
[8]. This, of course, doubles the cost of both memory access
and interprocessor communication.
then performs a binary search on these
splitters for each of its input values and then uses the results
to route the values to the appropriate destination, after which local
sorting is done to complete the sorting process. The first difficulty
with this approach is the work involved in gathering and sorting the
splitters. A larger value of s results in better load
balancing, but it also increases the overhead. The second difficulty
is
that no matter how the routing is scheduled, there exist inputs that
give rise to large variations in the number of elements destined for
different processors, and this in turn results in an inefficient use
of the communication bandwidth. Moreover, such an irregular
communication scheme cannot take advantage of the regular
communication primitives proposed under the MPI standard [20].
The final difficulty with the original approach is that duplicate values
are accommodated by tagging each item with some unique value
[8]. This, of course, doubles the cost of both memory access
and interprocessor communication.
In our version of sample sort,
we incur no overhead in obtaining ![]() samples from each processor and in sorting these samples
to identify the splitters. Because of this very high
oversampling, we are able to replace the irregular routing with
exactly two calls to our transpose primitive, and we are able
to efficiently accommodate the presence of duplicates without
resorting to tagging. The pseudo code
for our algorithm is as follows:
samples from each processor and in sorting these samples
to identify the splitters. Because of this very high
oversampling, we are able to replace the irregular routing with
exactly two calls to our transpose primitive, and we are able
to efficiently accommodate the presence of duplicates without
resorting to tagging. The pseudo code
for our algorithm is as follows:
We can establish the complexity of this algorithm with high
probability - that is with probability ![]() for some positive constant
for some positive constant ![]() . But before doing this, we need
the results of the following theorem, whose proof has been omitted
for brevity [14].
. But before doing this, we need
the results of the following theorem, whose proof has been omitted
for brevity [14].
Theorem 1: The number of elements in each bucket at the
completion of Step (1) is at most ![]() , the
number of elements received by each processor at the completion of
Step (7) is at most
, the
number of elements received by each processor at the completion of
Step (7) is at most ![]() , and the number of
elements exchanged by any two processors in Step (7) is at most
, and the number of
elements exchanged by any two processors in Step (7) is at most
![]() , all with high probability for any
, all with high probability for any ![]() ,
,
![]() (
( ![]() for duplicates),
for duplicates),
![]() (
( ![]() for duplicates),
and
for duplicates),
and ![]() .
.
With these bounds on the values of ![]() ,
, ![]() , and
, and ![]() ,
the analysis of our sample sort algorithm is as follows. Steps
(1), (3), (4), (6), and (8) involve no
communication and are dominated by the cost of the sequential sorting
in Step (3) and the merging in Step (8). Sorting integers
using radix sort requires O
,
the analysis of our sample sort algorithm is as follows. Steps
(1), (3), (4), (6), and (8) involve no
communication and are dominated by the cost of the sequential sorting
in Step (3) and the merging in Step (8). Sorting integers
using radix sort requires O ![]() time, whereas sorting
floating point numbers using merge sort requires O
time, whereas sorting
floating point numbers using merge sort requires O ![]() WY time. Step (8) requires O
WY time. Step (8) requires O ![]() time if we merge the sorted subsequences in a binary tree
fashion. Steps (2), (5), and (7) call the
communication primitives transpose, bcast, and
transpose, respectively. The analysis of these primitives in
[6] shows that with high probability these three steps
require
time if we merge the sorted subsequences in a binary tree
fashion. Steps (2), (5), and (7) call the
communication primitives transpose, bcast, and
transpose, respectively. The analysis of these primitives in
[6] shows that with high probability these three steps
require ![]() ,
,
![]() , and
, and ![]() , respectively.
Hence, with high probability, the overall complexity of our sample
sort algorithm is given (for floating point numbers) by
, respectively.
Hence, with high probability, the overall complexity of our sample
sort algorithm is given (for floating point numbers) by
![]()
for ![]() .
.
Clearly, our algorithm is asymptotically optimal with very small coefficients. But it is also important to perform an empirical evaluation of our algorithm using a wide variety of benchmarks. Our algorithm was implemented and tested on nine different benchmarks, each of which had both a 32-bit integer version (64-bit on the Cray T3D) and a 64-bit double precision floating point number (double) version. The details and the rationale for these benchmarks are described in Appendix A. Table i displays the performance of our sample sort as a function of input distribution for a variety of input sizes. The results show that the performance is essentially independent of the input distribution. There is a slight preference for those benchmarks which contain high numbers of duplicates, but this is attributed to the reduced time required for sequential sorting in Step (3).
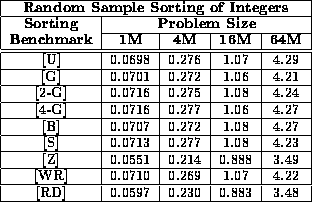
Table i: Total execution time (in seconds) for sample sorting a variety of
benchmarks on a 64 node Cray T3D.
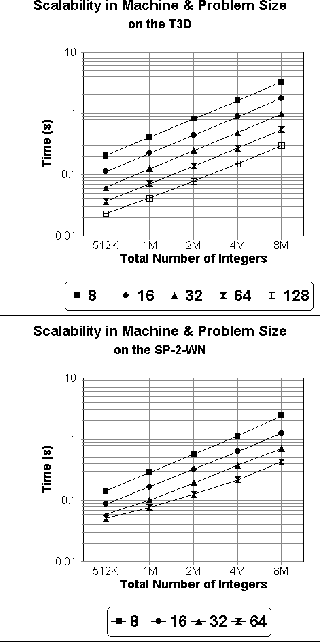
Figure 3: Scalability with respect to problem size of sample sorting integers
from the [U]
benchmark, for differing numbers of processors, on the Cray T3D and the IBM
SP-2-WN.
Table ii examines the scalability of our sample sort as a function of machine size. It shows that for a given input size n the execution time scales almost inversely with the number of processors p.
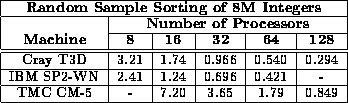
Table ii: Total execution time (in seconds) for sorting 8M integers
from the [WR] benchmark
on a variety of machines and processors. A hyphen indicates
that that particular platform was unavailable to us.
Figure 3 examines the scalability of our sample sort as a function of problem size, for differing numbers of processors. It shows that for a fixed number of processors there is an almost linear dependence between the execution time and the total number of elements n. Finally, Table iii compares our results on the Class A NAS Benchmark for integer sorting (IS) with the best times reported for the TMC CM-5 and the Cray T3D. Note that the name of this benchmark is somewhat misleading. Instead of requiring that the integers be placed in sorted order as we do, the benchmark only requires that they be ranked without any reordering, which is a significantly simpler task. We believe that our results, which were obtained using high-level, portable code, compare favorably with the other reported times, which were obtained by the vendors using machine-specific implementations and perhaps system modifications.
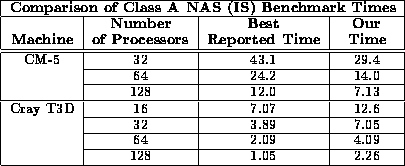
Table iii: Comparison of our execution time (in seconds) with the best
reported times for the Class A NAS Parallel Benchmark for integer
sorting. Note that while we actually place the integers in sorted
order, the benchmark only requires that they be ranked without
actually reordering.
See [14] for additional performance data and comparisons with other published results.