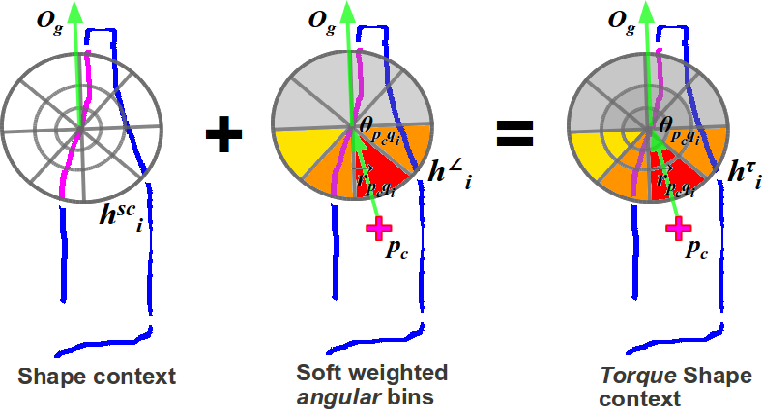
We present a novel mid-level contour-based object recognition approach that exploits the "image-torque" operator [1] for the purpose of recognizing generic object shape categories, e.g. bottles, round, elongated etc. To do this, we introduce a robust shape matching descriptor, termed the torque shape-context that embeds border ownership information via image-torque into the shape-context descriptor of [2]. This improves the discriminative power of the descriptor when matching partial contour fragments. In addition, by applying a Fast Fourier Transform (FFT) over its angular components, we are able to handle changes in scale and rotation. We show, using several diverse datasets, that our approach is able to detect multiple objects shape categories in complex scenes containing clutter, occlusions, scale and rotation reliably.
Given an image torque "fixation" point, edges that contribute to the torque are then embedded with border ownership information: the side nearer to the fixation point is considered "foreground" while the other side is "background". We then apply a truncated Gaussian to weigh angular bins towards the foreground side. Combining the original shape-context and the weighted angular bins yields the torque-shape context.
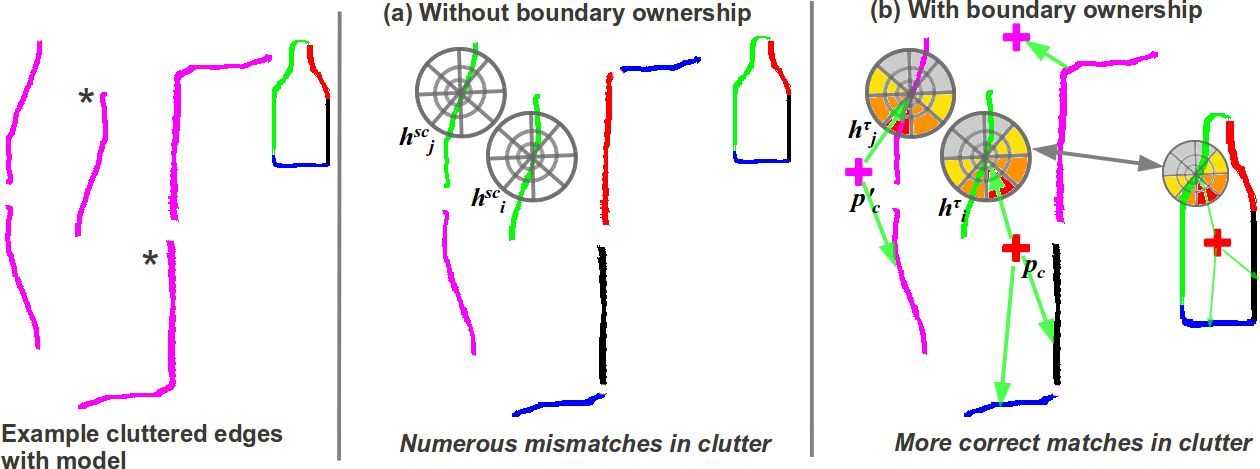 When matching contour fragments in clutter, border ownership increases the discriminatory power of the torque shape-context, producing more accurate matches.
When matching contour fragments in clutter, border ownership increases the discriminatory power of the torque shape-context, producing more accurate matches.
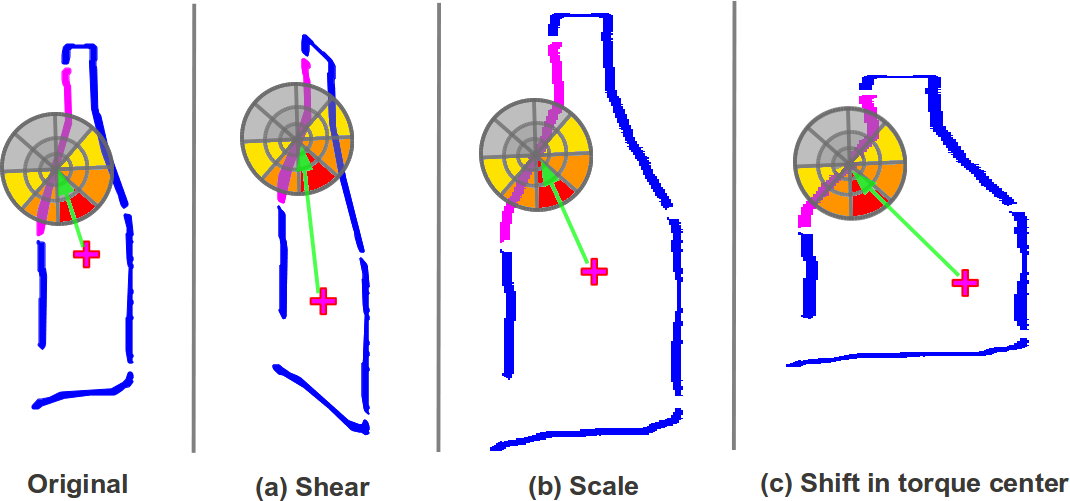 Soft weights applied on the angular bins also makes the descriptor robust against typical deformations and noise in localizing the torque fixation point.
Soft weights applied on the angular bins also makes the descriptor robust against typical deformations and noise in localizing the torque fixation point.
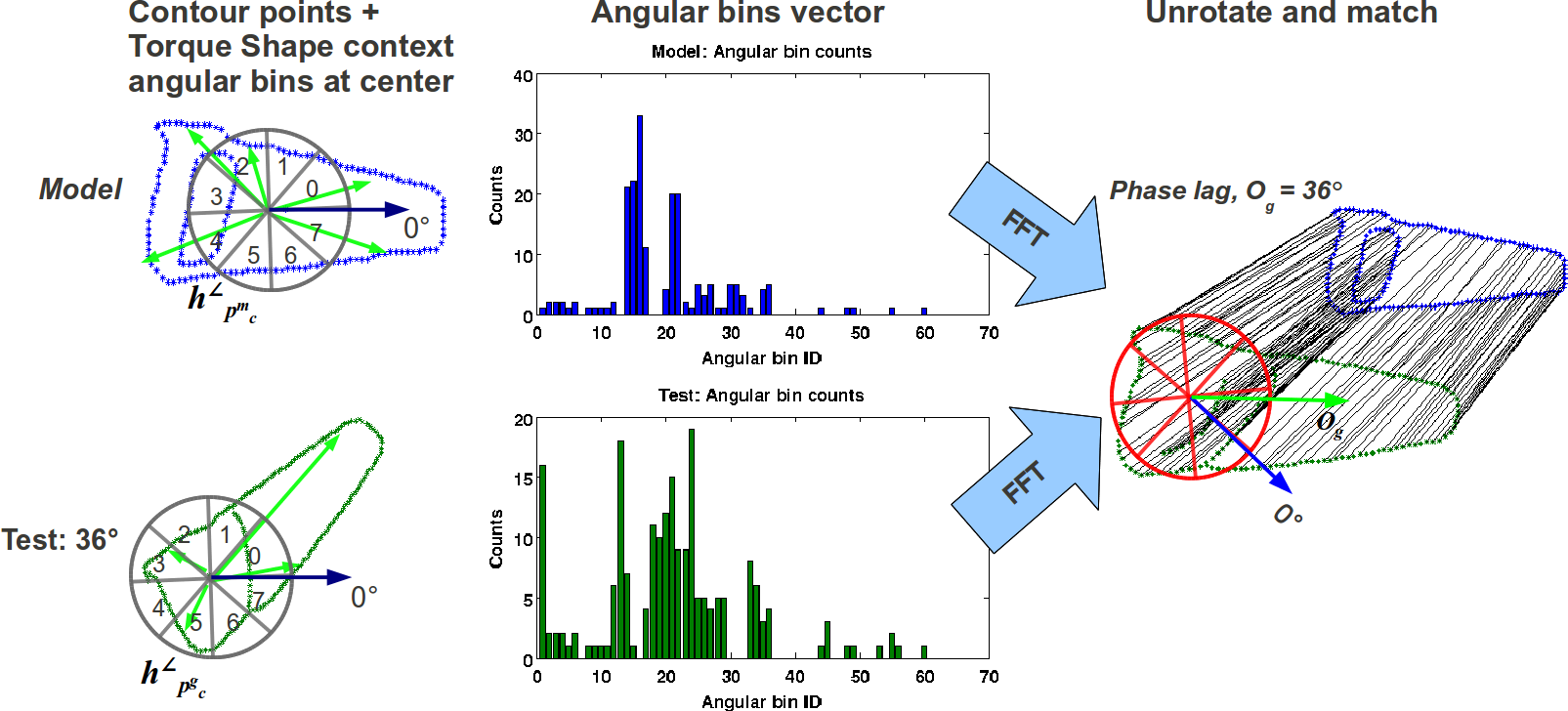 By applying an FFT over angular bins of the torque shape-context centered at the torque fixation point, we are able to estimate the amount of rotation between the model and target, enabling us to compensate for rotation and scale changes during matching.
By applying an FFT over angular bins of the torque shape-context centered at the torque fixation point, we are able to estimate the amount of rotation between the model and target, enabling us to compensate for rotation and scale changes during matching.
We adapt the modulated torque-based detection method of [3] using matching scores derived from torque shape-context. Example detections of "Mug" from the UMD Clutter dataset is shown below. Note that there are two instances of "Mug" in the sequences:
For each detection, we show from left to right, the matching scores (red means higher), modulated torque and the final detection as bounding boxes.
Questions? Please contact cteo "at" umd dot edu