For each experiment, the input is evenly distributed amongst the
processors. The output consists of the elements in non-descending order
arranged amongst the processors so that the elements at each processor
are in sorted order and no element at processor 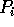 is
greater than any element at processor
is
greater than any element at processor 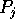 , for all i < j.
, for all i < j.
Two variations were allowed in our experiments. First, radix sort was used to sequentially sort integers, whereas merge sort was used to sort double precision floating point numbers (doubles). Second, different implementations of the communication primitives were allowed for each machine. Wherever possible, we tried to use the vendor supplied implementations.
In fact, IBM does provide all of our communication primitives as part of its machine specific Collective Communication Library (CCL) [8]. As one might expect, they were faster than the high level Split-C implementation.
The graphs in Figures 1 and 2 display the performance of our sample sort as a function of input distribution for a variety of input sizes. In each case, the performance is essentially independent of the input distribution. These figures present results obtained on a 64 node Cray T3D; results obtained from other machines validate this claim as well. Because of this independence, the remainder of this section will only discuss the performance of our sample sort on the single benchmark [U].
Figure 1: Performance is independent of input distribution for integers.
Figure 2: Performance is independent of input distribution for
doubles.
The results in Tables I and II together with their
graphs in Figure 3 examine the scalability of our sample sort as
a function of machine size. Results are shown for the CM-5, the
SP-2-WN, the SP2-TN2, and the T3D. Bearing in mind that these graphs
are log-log plots, they show that for a given input size n the
execution time scales almost inversely with the number of processors
p. While this is certainly the expectation of our analytical model
for doubles, it might at first appear to exceed our prediction of an
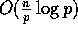 computational complexity for integers.
However, the appearance of an inverse relationship is still quite
reasonable when we note that this
computational complexity for integers.
However, the appearance of an inverse relationship is still quite
reasonable when we note that this 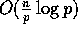 complexity
is entirely due to the merging in Step (8), and in practice, as
we show later with Figure 6, Step (8) only accounts for
about
complexity
is entirely due to the merging in Step (8), and in practice, as
we show later with Figure 6, Step (8) only accounts for
about 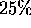 of the observed execution time. Note that the complexity
of Step 8 could be reduced to
of the observed execution time. Note that the complexity
of Step 8 could be reduced to 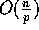 for integers
using radix sort, but the resulting execution time would be slower.
for integers
using radix sort, but the resulting execution time would be slower.
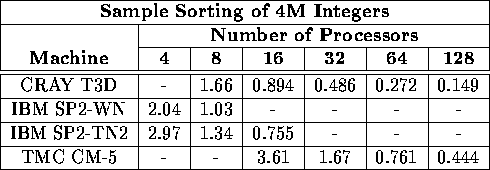
Table i: Total execution time (in seconds) for sorting 4M integers
on a variety of machines and processors. A hyphen indicates
that that particular platform was unavailable to us.
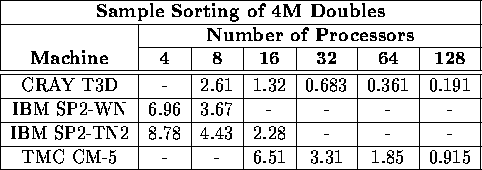
Table ii: Total execution time (in seconds) for sorting 4M doubles
on a variety of machines and processors.
A hyphen indicates
that that particular platform was unavailable to us.
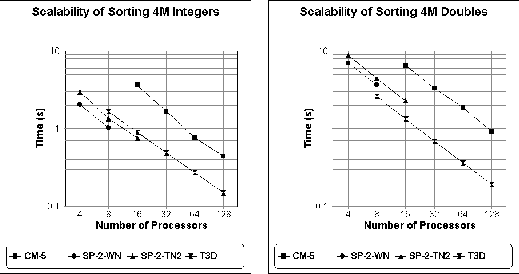
Figure 3: Scalability of sorting integers and doubles with respect
to machine size.
Figures 4 and 5 examine the scalability of our sample sort
as a function of problem size, for differing numbers of processors.
They show that for a fixed number of processors there is an almost
linear dependence between the execution time and the total number of
elements n. While this is certainly the expectation of our analytic
model for integers, it might at first appear to exceed our
prediction of a 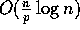 computational complexity for
floating point values. However, this appearance of a linear
relationship is still quite reasonable when we consider that for the
range of values shown
computational complexity for
floating point values. However, this appearance of a linear
relationship is still quite reasonable when we consider that for the
range of values shown  differs by only a factor of
differs by only a factor of  .
.
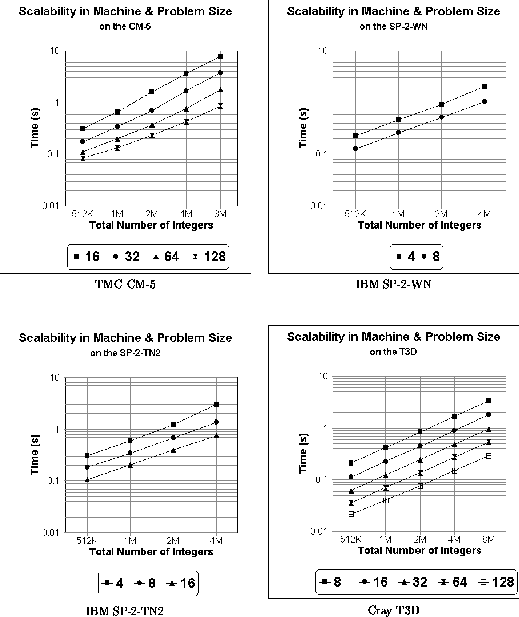
Figure 4: Scalability of sorting integers with respect to problem
size, for differing numbers of processors.
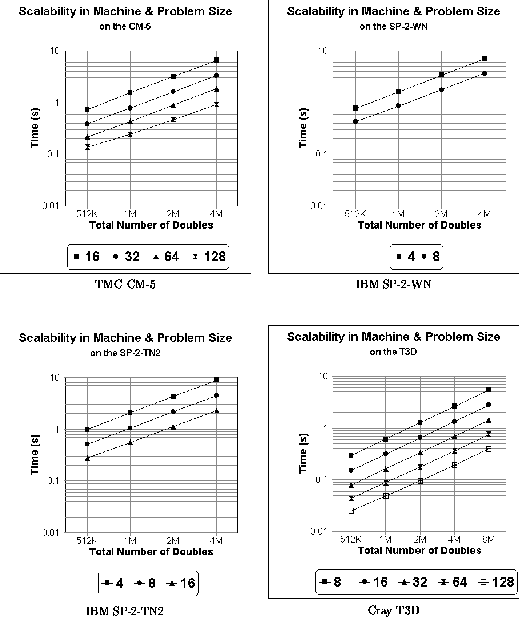
Figure 5: Scalability of sorting doubles with respect to problem size,
for differing numbers of processors.
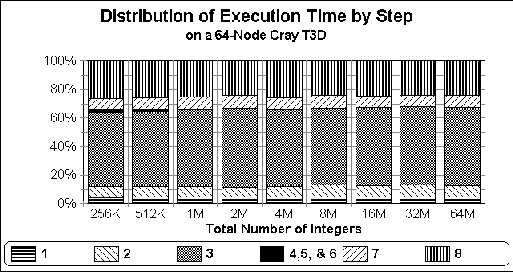
Figure 6: Distribution of execution time amongst the eight steps of sample
sort for integers. Times are obtained on a 64 node T3D.
Next, the graphs in Figures 6 and 7 examine the
relative costs of the eight steps in our sample sort on a 64 node T3D.
Notice that the sequential sorting and merging performed in Steps
(3) and (8) consume nearly 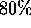 of the execution time,
whereas the two transpose operations in Steps (2) and
(7) together consume only about
of the execution time,
whereas the two transpose operations in Steps (2) and
(7) together consume only about 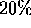 of the execution time (and
less for doubles). Similar results were obtained for all of our
benchmarks, showing that our algorithm is extremely efficient in its
communication performance.
of the execution time (and
less for doubles). Similar results were obtained for all of our
benchmarks, showing that our algorithm is extremely efficient in its
communication performance.
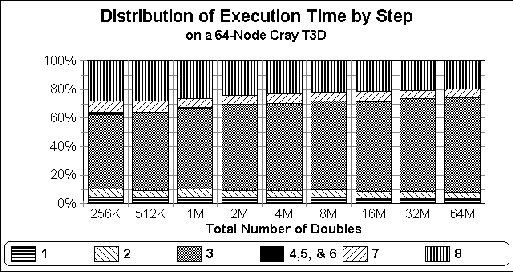
Figure 7: Distribution of execution time amongst the eight steps of sample
sort for doubles. Times are obtained on a 64 node T3D.
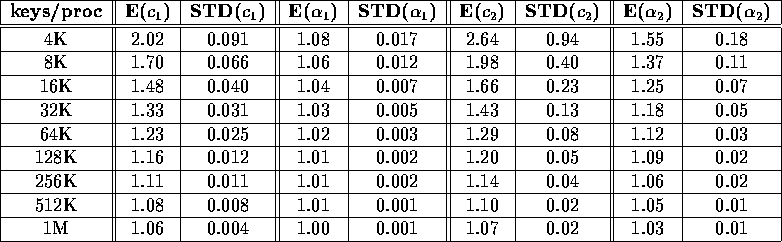
Table iii: Statistical evaluation of the experimentally observed values of
the algorithm coefficients on a 64 node T3D.
Finally, Table III shows the experimentally derived expected
value (E) and sample standard deviation (STD) of the coefficients
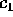 ,
, 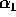 ,
, 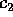 , and
, and 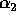 used to describe the
complexity of our algorithm in Section 3. For each input size,
the values were obtained by analyzing data collected while sorting the
[G], [B], [2-G], [4-G], and [S]
benchmarks. Each of these benchmarks was generated and sorted 20
times, each time using a different seed for the random number
generator. The experimentally derived values for
used to describe the
complexity of our algorithm in Section 3. For each input size,
the values were obtained by analyzing data collected while sorting the
[G], [B], [2-G], [4-G], and [S]
benchmarks. Each of these benchmarks was generated and sorted 20
times, each time using a different seed for the random number
generator. The experimentally derived values for 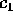 ,
, 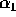 ,
,
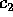 , and
, and 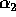 agree closely with the theoretically derived
values of
agree closely with the theoretically derived
values of 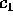 (2),
(2), 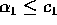 ,
, 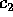 (2.48), and
(2.48), and 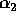 (1.33) for
(1.33) for 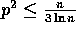 .
.