Our six sorting benchmarks are defined as follows, in which MAX is
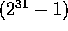 for integers and approximately
for integers and approximately 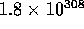 for doubles:
for doubles:
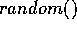 . This function,
which returns integers in the range 0 to
. This function,
which returns integers in the range 0 to 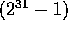 , is initialized
by each processor
, is initialized
by each processor 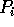 with the value
with the value 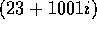 . For the
double data type, we ``normalize'' these values
by first assigning the integer returned by random() a
randomly chosen sign bit
and then scaling the result by
. For the
double data type, we ``normalize'' these values
by first assigning the integer returned by random() a
randomly chosen sign bit
and then scaling the result by 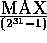 .
.
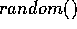 and then dividing the result
by four. For the double type, we first normalize the values
returned by
and then dividing the result
by four. For the double type, we first normalize the values
returned by 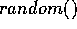 in the manner described for [U].
in the manner described for [U].
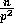 elements at each processor to be
random numbers between 0 and
elements at each processor to be
random numbers between 0 and 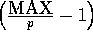 ,
the second
,
the second 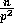 elements at each processor to be
random numbers between
elements at each processor to be
random numbers between 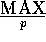 and
and 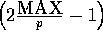 , and
so forth.
, and
so forth.
 elements to be
random numbers between
elements to be
random numbers between  and
and
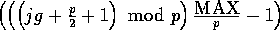 , the second
, the second
 elements at each processor to be random numbers between
elements at each processor to be random numbers between
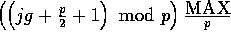 and
and
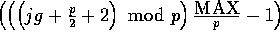 , and so forth.
, and so forth.
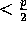 , then we set all
, then we set all 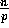 elements at that
processor to be random numbers between
elements at that
processor to be random numbers between 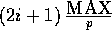 and
and
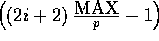 , and so forth.
Otherwise, we set all
, and so forth.
Otherwise, we set all 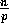 elements to be random numbers
between
elements to be random numbers
between 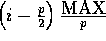 and
and
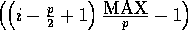 , and so forth.
, and so forth.
We selected these six benchmarks for a variety of reasons. Previous
researchers have used the Uniform, Gaussian, and Zero benchmarks,
and so we too included them for purposes of
comparison. But benchmarks should be designed to illicit the worst case
behavior from an algorithm, and in this sense the Uniform benchmark is
not appropriate. For example, for  , one would expect that the
optimal choice of the splitters in the Uniform benchmark would be those
which partition the range of possible values into equal intervals. Thus,
algorithms which try to guess the splitters might perform misleadingly well
on such an input. In this respect, the Gaussian benchmark is more telling.
But we also wanted to find benchmarks which would evaluate the cost of
irregular communication. Thus, we wanted to include benchmarks for
which an algorithm which uses a single phase of routing would find
contention difficult or even impossible to avoid. A naive approach to
rearranging the data would perform poorly on the Bucket Sorted
benchmark. Here, every processor would try to route data to the same processor
at the same time, resulting in poor utilization of communication
bandwidth. This problem might be avoided by an algorithm in which
at each processor the elements are first grouped by destination and then
routed according to the specifications of a sequence of p destination
permutations. Perhaps the most straightforward way to do this is by
iterating
over the possible communication strides. But such a strategy would
perform poorly with the g-Group benchmark, for a suitably chosen value of
g. In this case, using stride
iteration, those processors which belong to a particular group all route data
to the same subset of g destination processors. This subset of
destinations is selected so that, when the g processors
route to this subset, they choose the processors in exactly the same order,
producing contention and possibly stalling. Alternatively, one
can synchronize the processors after each permutation, but this in
turn will reduce the communication bandwidth by a factor of
, one would expect that the
optimal choice of the splitters in the Uniform benchmark would be those
which partition the range of possible values into equal intervals. Thus,
algorithms which try to guess the splitters might perform misleadingly well
on such an input. In this respect, the Gaussian benchmark is more telling.
But we also wanted to find benchmarks which would evaluate the cost of
irregular communication. Thus, we wanted to include benchmarks for
which an algorithm which uses a single phase of routing would find
contention difficult or even impossible to avoid. A naive approach to
rearranging the data would perform poorly on the Bucket Sorted
benchmark. Here, every processor would try to route data to the same processor
at the same time, resulting in poor utilization of communication
bandwidth. This problem might be avoided by an algorithm in which
at each processor the elements are first grouped by destination and then
routed according to the specifications of a sequence of p destination
permutations. Perhaps the most straightforward way to do this is by
iterating
over the possible communication strides. But such a strategy would
perform poorly with the g-Group benchmark, for a suitably chosen value of
g. In this case, using stride
iteration, those processors which belong to a particular group all route data
to the same subset of g destination processors. This subset of
destinations is selected so that, when the g processors
route to this subset, they choose the processors in exactly the same order,
producing contention and possibly stalling. Alternatively, one
can synchronize the processors after each permutation, but this in
turn will reduce the communication bandwidth by a factor of
 . In the worst case scenario, each processor needs to send data to a
single processor a unique stride away. This is the case of the Staggered
benchmark, and the result is a reduction of the communication bandwidth
by a factor of p. Of course, one can correctly object that both the
g-Group benchmark and the Staggered benchmark have been tailored to thwart
a routing scheme which iterates over the possible strides, and that another
sequences of permutations might be found which performs better. This is
possible, but at the same time we are unaware of any single phase
deterministic algorithm which could avoid an equivalent challenge.
. In the worst case scenario, each processor needs to send data to a
single processor a unique stride away. This is the case of the Staggered
benchmark, and the result is a reduction of the communication bandwidth
by a factor of p. Of course, one can correctly object that both the
g-Group benchmark and the Staggered benchmark have been tailored to thwart
a routing scheme which iterates over the possible strides, and that another
sequences of permutations might be found which performs better. This is
possible, but at the same time we are unaware of any single phase
deterministic algorithm which could avoid an equivalent challenge.