Consider the problem of sorting n elements equally distributed
amongst p processors, where we assume without loss of generality that p
divides n evenly. The idea behind sample sort is to find a set of
p - 1 splitters to partition the n input elements
into p groups indexed from 0 up to p - 1 such that every element
in the 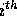 group is less than or equal to each of the elements in
the
group is less than or equal to each of the elements in
the 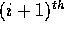 group, for
group, for 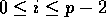 . Then the task of
sorting each of the p groups
can be turned over to the correspondingly indexed processor, after which
the n elements will be arranged in sorted order. The
efficiency of this algorithm obviously depends on how well we divide the
input, and this in turn depends on how well we choose the splitters.
One way to choose the splitters is by randomly sampling the input elements
at each processor - hence the name sample sort.
. Then the task of
sorting each of the p groups
can be turned over to the correspondingly indexed processor, after which
the n elements will be arranged in sorted order. The
efficiency of this algorithm obviously depends on how well we divide the
input, and this in turn depends on how well we choose the splitters.
One way to choose the splitters is by randomly sampling the input elements
at each processor - hence the name sample sort.
Previous versions of sample sort
[20,10,17,15] have
randomly chosen s samples from the 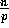 elements at each
processor, routed them to a single processor, sorted them at that processor,
and then selected every
elements at each
processor, routed them to a single processor, sorted them at that processor,
and then selected every 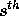 element as a splitter. Each processor
element as a splitter. Each processor
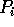 then performs a binary search on these splitters for each of its input
values and then uses the results to route the values to the appropriate
destination, after which
local sorting is done to complete the sorting process.
The first difficulty with this approach
is the work involved in gathering and sorting the splitters. A larger
value of s results in better load balancing, but it also increases the
overhead. The other difficulty is that no matter how the routing is
scheduled, there exist inputs that give rise to large variations in
the number of elements
destined for different processors, and this in turn results in an inefficient
use of the
communication bandwidth. Moreover, such an irregular communication scheme
cannot take advantage of the regular communication primitives proposed
under the MPI standard [27].
then performs a binary search on these splitters for each of its input
values and then uses the results to route the values to the appropriate
destination, after which
local sorting is done to complete the sorting process.
The first difficulty with this approach
is the work involved in gathering and sorting the splitters. A larger
value of s results in better load balancing, but it also increases the
overhead. The other difficulty is that no matter how the routing is
scheduled, there exist inputs that give rise to large variations in
the number of elements
destined for different processors, and this in turn results in an inefficient
use of the
communication bandwidth. Moreover, such an irregular communication scheme
cannot take advantage of the regular communication primitives proposed
under the MPI standard [27].
In our solution, we incur no overhead in obtaining 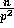 samples from each processor and in sorting these samples to identify
the splitters. Because of this very high oversampling, we are
able to replace the irregular routing with exactly two calls to
our transpose primitive.
samples from each processor and in sorting these samples to identify
the splitters. Because of this very high oversampling, we are
able to replace the irregular routing with exactly two calls to
our transpose primitive.
The pseudo code for our algorithm is as follows:
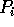
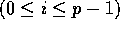 randomly assigns
each of its
randomly assigns
each of its
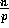 elements to one of p buckets. With high probability,
no bucket will receive more than
elements to one of p buckets. With high probability,
no bucket will receive more than 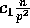 elements, where
elements, where 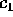 is a constant to be defined later.
is a constant to be defined later.
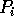 routes the contents of bucket
j to processor
routes the contents of bucket
j to processor 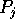 , for
, for 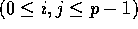 . Since with high
probability no bucket will receive more than
. Since with high
probability no bucket will receive more than 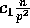 elements,
this is equivalent to performing a transpose operation with block
size
elements,
this is equivalent to performing a transpose operation with block
size 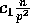 .
.
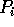 sorts the
sorts the
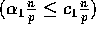 values received in
Step (2) using an appropriate sequential sorting algorithm. For
integers we use the radix sort algorithm, whereas for floating point
numbers we use the merge sort algorithm.
values received in
Step (2) using an appropriate sequential sorting algorithm. For
integers we use the radix sort algorithm, whereas for floating point
numbers we use the merge sort algorithm.
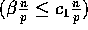 elements,
processor
elements,
processor 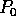 selects each
selects each
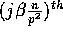 element as a
splitter, for
element as a
splitter, for 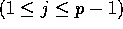 .
By default, the first and last splitters
are respectively the
smallest and largest values allowed by the data type used.
.
By default, the first and last splitters
are respectively the
smallest and largest values allowed by the data type used.
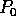 broadcasts the p - 1
intermediate splitters to the other p - 1 processors.
broadcasts the p - 1
intermediate splitters to the other p - 1 processors.
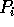 finds the positions of the
splitters in its local array of sorted elements by performing a binary
search for each of these splitters.
finds the positions of the
splitters in its local array of sorted elements by performing a binary
search for each of these splitters.
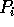 routes the subsequence falling
between splitter j and splitter j + 1
to processor
routes the subsequence falling
between splitter j and splitter j + 1
to processor 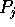 , for
, for 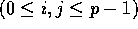 . Since with high
probability no sequence will contain more than
. Since with high
probability no sequence will contain more than 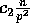 elements, where
elements, where 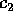 is a constant to be defined later, this is equivalent
to performing a transpose operation with block size
is a constant to be defined later, this is equivalent
to performing a transpose operation with block size
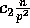 .
.
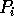 merges the p sorted subsequences
received in Step (7) to produce the
merges the p sorted subsequences
received in Step (7) to produce the 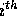 column of the sorted
array. Note that, with high probability, no processor has received more
than
column of the sorted
array. Note that, with high probability, no processor has received more
than 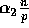 elements, where
elements, where 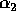 is a constant to be
defined later.
is a constant to be
defined later.
We can establish the complexity of this algorithm with high probability -
that is with probability 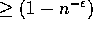 for some positive
constant
for some positive
constant  . But before doing this, we need to establish
the results of the following four lemmas.
. But before doing this, we need to establish
the results of the following four lemmas.
Lemma 1: At the completion of Step (1), the number of
elements in each bucket is at most 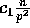 with high
probability, for any
with high
probability, for any 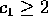 and
and 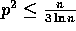 .
.
Proof: The probability that exactly 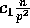 elements are placed in a particular bucket in Step (1) is given by
the binomial distribution
elements are placed in a particular bucket in Step (1) is given by
the binomial distribution

where 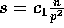 ,
, 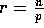 , and
, and 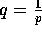 .
Using the following Chernoff bound [12] for estimating the tail of a
binomial distribution
.
Using the following Chernoff bound [12] for estimating the tail of a
binomial distribution

the probability that a particular bucket will contain at least
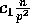 elements can be bounded by
elements can be bounded by
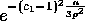 . Hence, the probability that any
of the
. Hence, the probability that any
of the 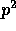 buckets contains at least
buckets contains at least 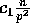 elements can be
bounded by
elements can be
bounded by 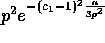 , and Lemma 1 follows.
, and Lemma 1 follows.
Lemma 2: At the completion of Step (2), the total number of
elements received by processor 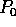 , which comprise the set of
samples from which the splitters are chosen,
is at most
, which comprise the set of
samples from which the splitters are chosen,
is at most 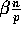 with high probability, for any
with high probability, for any 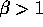 and
and 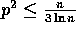 .
.
Proof: The probability that processor 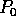 receives exactly
receives exactly
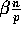 elements is given by the binomial distribution
elements is given by the binomial distribution
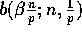 . Using the Chernoff bound for
estimating the tail of a binomial distribution, the probability that
processor
. Using the Chernoff bound for
estimating the tail of a binomial distribution, the probability that
processor 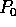 receives at least
receives at least 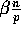 elements can be
bounded by
elements can be
bounded by 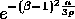 and Lemma 2 follows.
and Lemma 2 follows.
Lemma 3: At the completion of Step (7), the number of
elements received by each processor is at most 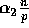 with high probability, for any
with high probability, for any 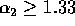 and
and
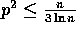 .
.
Proof: Establishing a bound on the number of elements
received by any processor in Step (7) is equivalent to establishing
a bound on the number of elements which fall between any two consecutive
splitters in the sorted order. But as Blelloch et al. [10]
observed, the number of elements which fall between any two consecutive
splitters in the sorted order can only be greater than 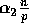 if in the sorted order there are less than
if in the sorted order there are less than 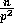 samples drawn from the
samples drawn from the 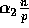 elements which
follow the first splitter. Since every element has an equal and independent
probability of being a sample, the probability that
exactly
elements which
follow the first splitter. Since every element has an equal and independent
probability of being a sample, the probability that
exactly 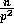 samples will be found amongst the
next
samples will be found amongst the
next 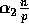 elements is given by the binomial distribution
elements is given by the binomial distribution
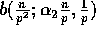 .
Using the following ``Chernoff'' type bound [18] for estimating the head
of a binomial distribution
.
Using the following ``Chernoff'' type bound [18] for estimating the head
of a binomial distribution

where 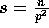 ,
, 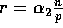 , and
, and 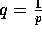 , the
probability that
, the
probability that 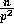 or less samples will be found
amongst the next
or less samples will be found
amongst the next 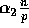 elements following any of the
p splitters can be bounded by
elements following any of the
p splitters can be bounded by
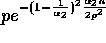 and
Lemma 3 follows.
and
Lemma 3 follows.
Lemma 4: The number of elements exchanged by any two
processors in Step (7) is at most 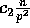 with high
probability, for any
with high
probability, for any 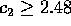 and
and 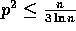 .
.
Proof: Since with high probability no processor can receive
more than 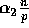 elements in Step (7), and since
the randomization in Step (1) means that each of these elements can
originate with equal probability from any of the p processors,
the probability that exactly
elements in Step (7), and since
the randomization in Step (1) means that each of these elements can
originate with equal probability from any of the p processors,
the probability that exactly 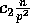 elements are exchanged
by any two particular processors is given by the binomial distribution
elements are exchanged
by any two particular processors is given by the binomial distribution
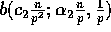 . Using the
Chernoff bound for estimating the tail of the binomial distribution,
the probability that any of the p processors exchange at least
. Using the
Chernoff bound for estimating the tail of the binomial distribution,
the probability that any of the p processors exchange at least
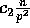 elements can be bounded by
elements can be bounded by
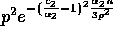 and Lemma 4 follows.
and Lemma 4 follows.
With these bounds on the values of 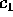 ,
, 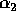 , and
, and 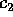 , the
analysis of our sample sort algorithm is as follows. Steps (1),
(3), (4), (6), and (8) involve no communication
and are dominated by the cost of the sequential sorting in Step (3)
and the merging in Step (8).
Sorting integers using radix sort requires
, the
analysis of our sample sort algorithm is as follows. Steps (1),
(3), (4), (6), and (8) involve no communication
and are dominated by the cost of the sequential sorting in Step (3)
and the merging in Step (8).
Sorting integers using radix sort requires 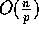 time,
whereas sorting floating point numbers using merge sort requires
time,
whereas sorting floating point numbers using merge sort requires
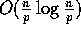 time.
Step (8) requires
time.
Step (8) requires 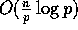 time if we merge the sorted
subsequences in a binary tree fashion.
Steps (2),
(5), and (7) call the communication primitives transpose,
bcast, and transpose, respectively. The analysis of these
primitives in [6] shows that with high probability these
three steps require
time if we merge the sorted
subsequences in a binary tree fashion.
Steps (2),
(5), and (7) call the communication primitives transpose,
bcast, and transpose, respectively. The analysis of these
primitives in [6] shows that with high probability these
three steps require
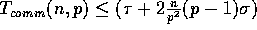 ,
,
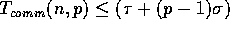 , and
, and
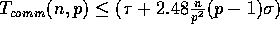 , respectively.
Hence, with high probability, the overall complexity of our sample sort
algorithm is given (for floating point numbers) by
, respectively.
Hence, with high probability, the overall complexity of our sample sort
algorithm is given (for floating point numbers) by
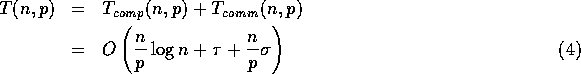
for 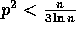 .
.
Clearly, our algorithm is asymptotically optimal with very small coefficients. But a theoretical comparison of our running time with previous sorting algorithms is difficult, since there is no consensus on how to model the cost of the irregular communication used by the most efficient algorithms. Hence, it is very important to perform an empirical evaluation of an algorithm using a wide variety of benchmarks, as we will do next.