|
Experiment #2
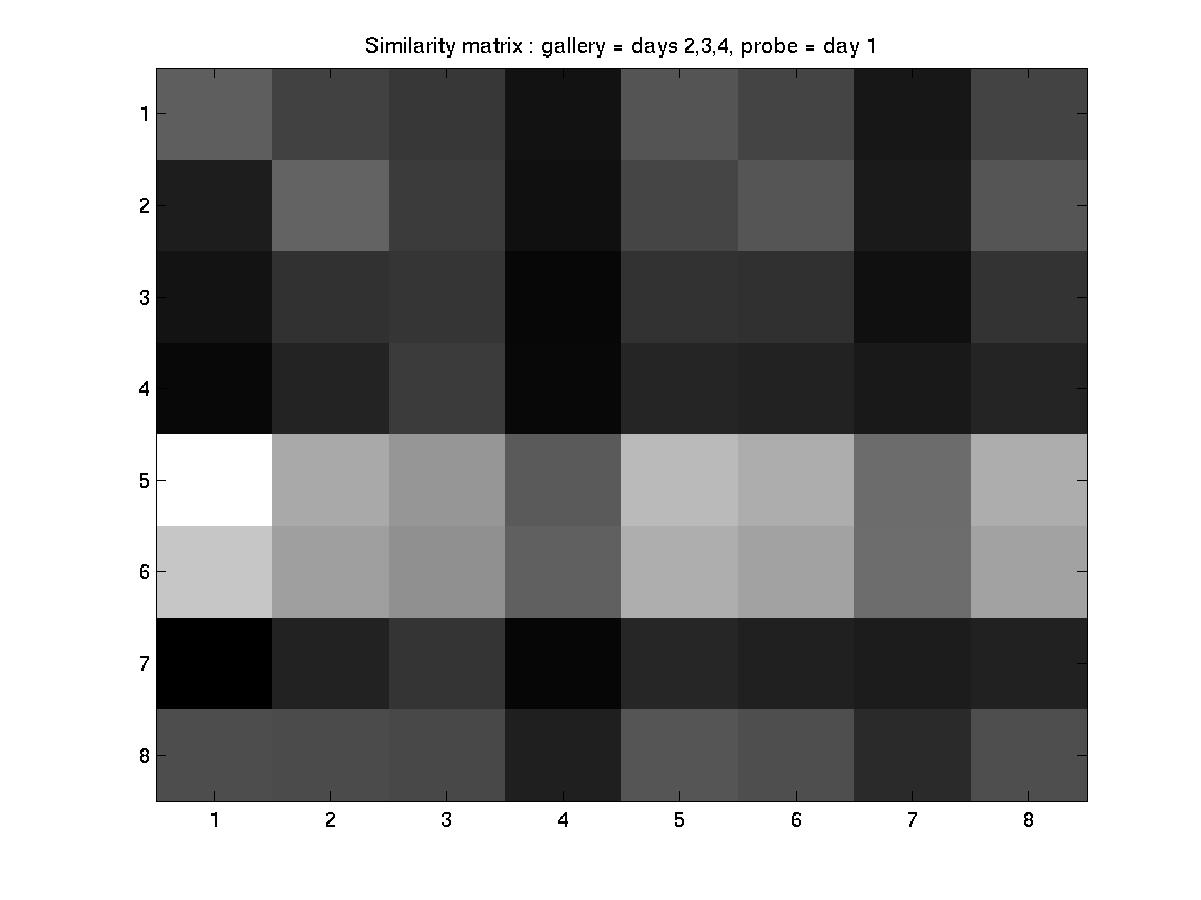
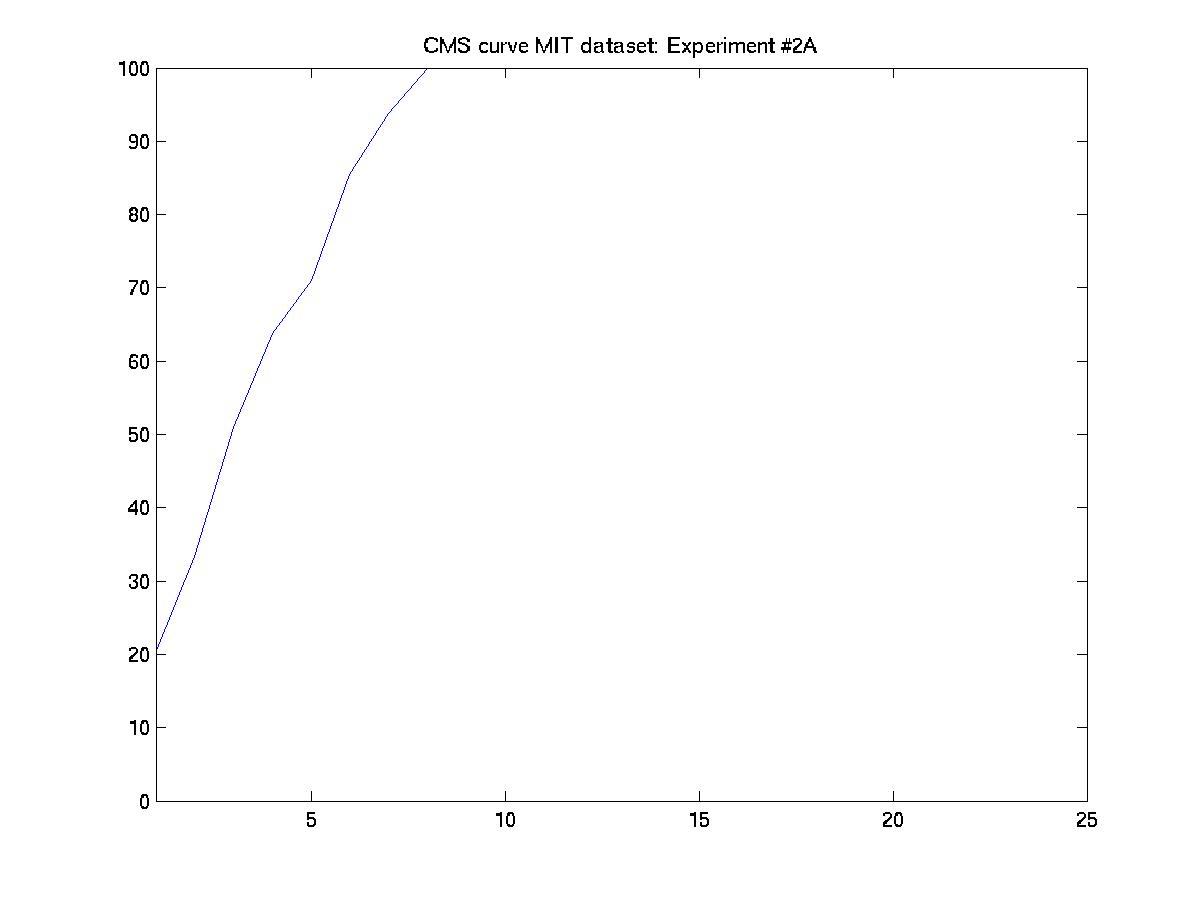
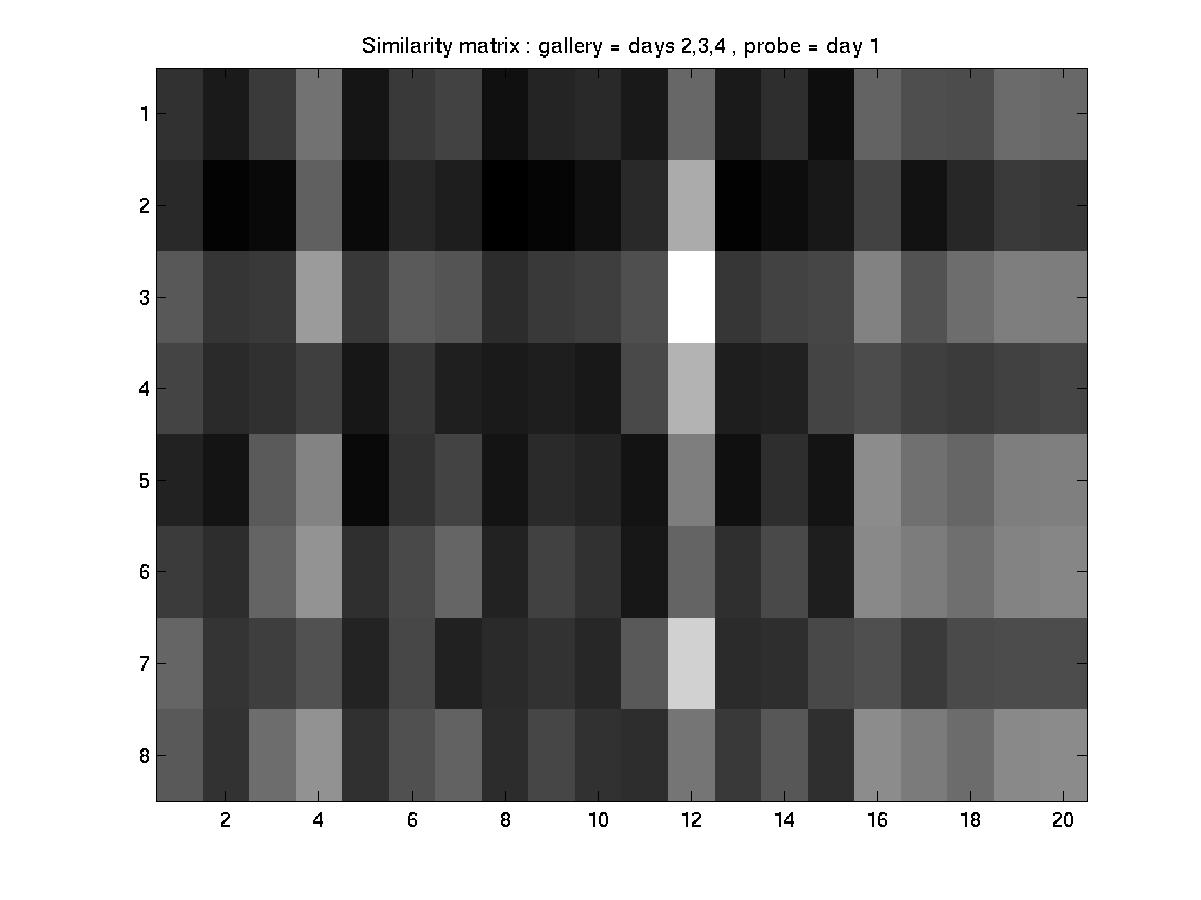
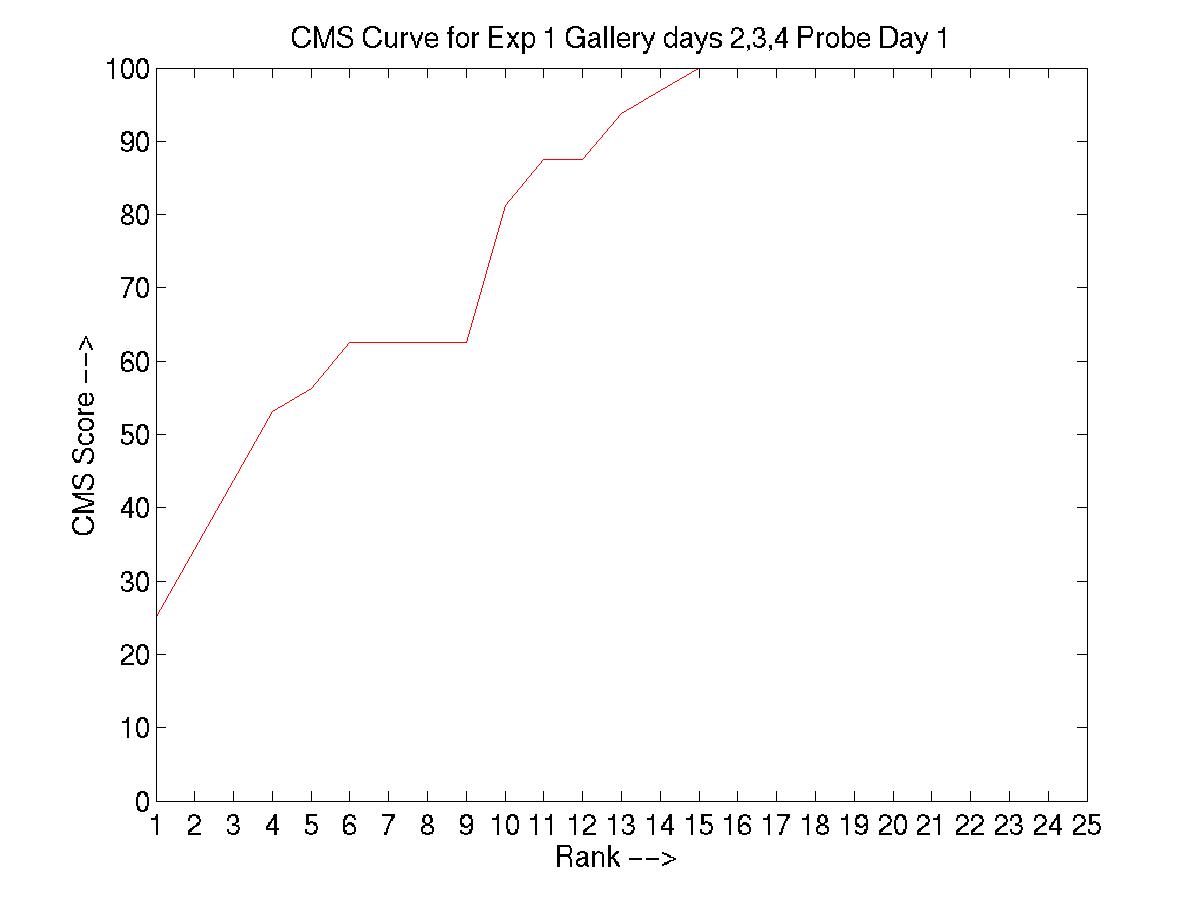
A. Day 030101 vs. days 031601, 032201, and 051001
B. Day 031601 vs. days 030101, 032201, and 051001
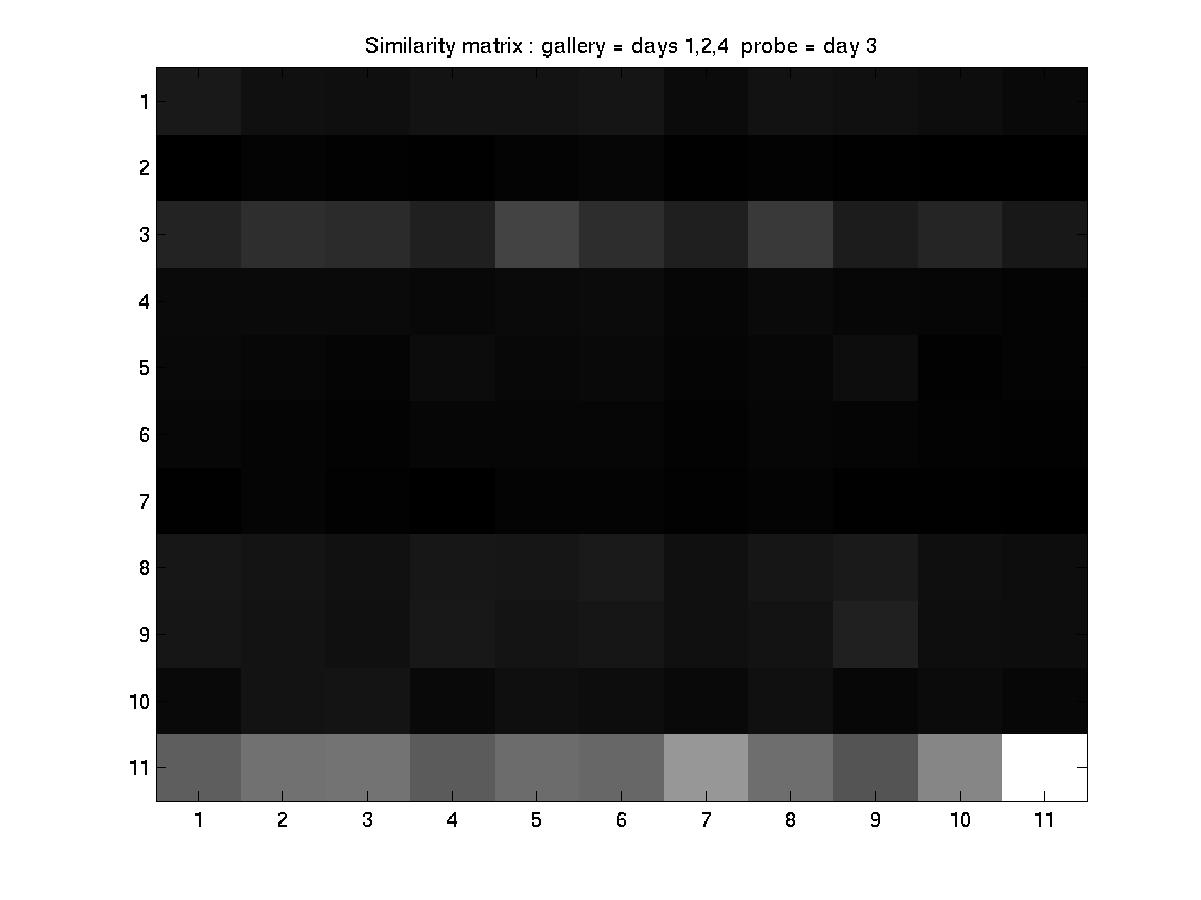
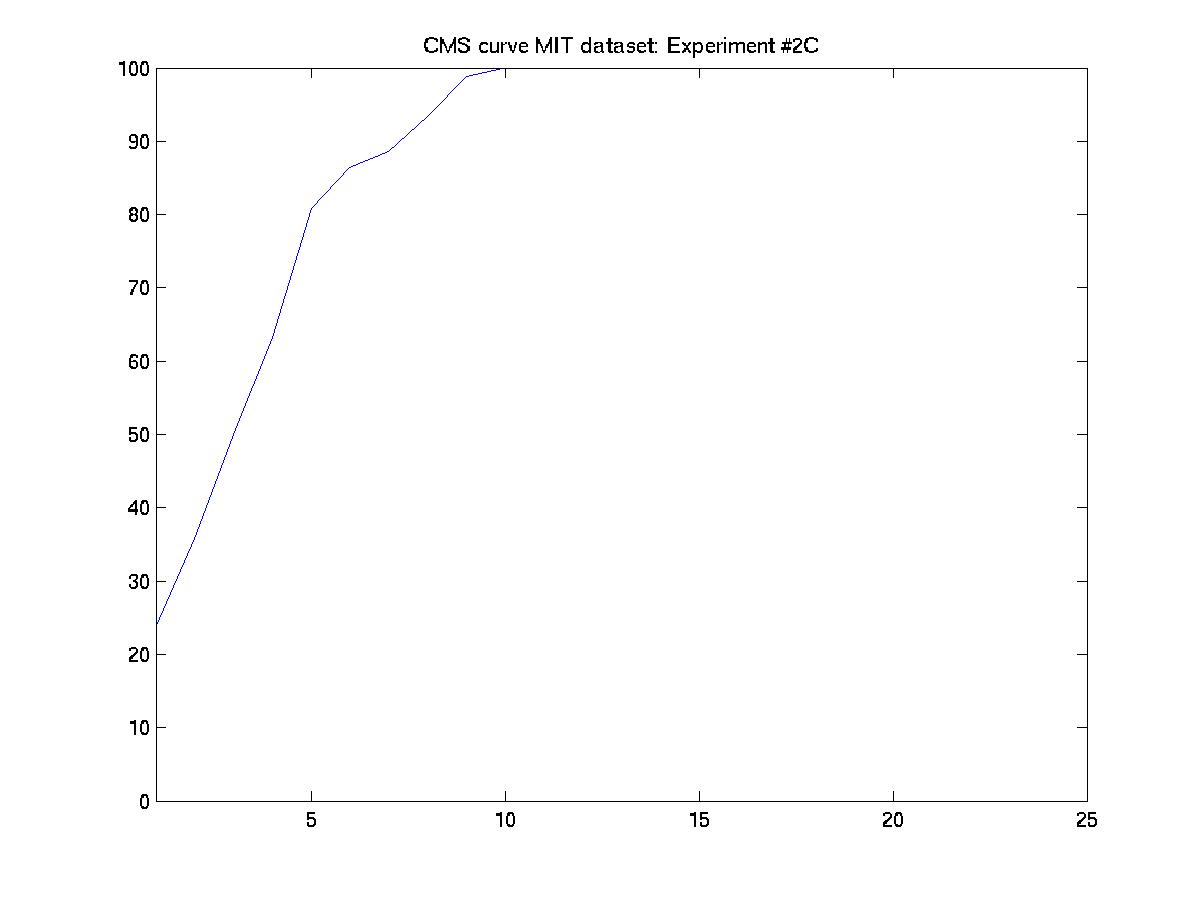
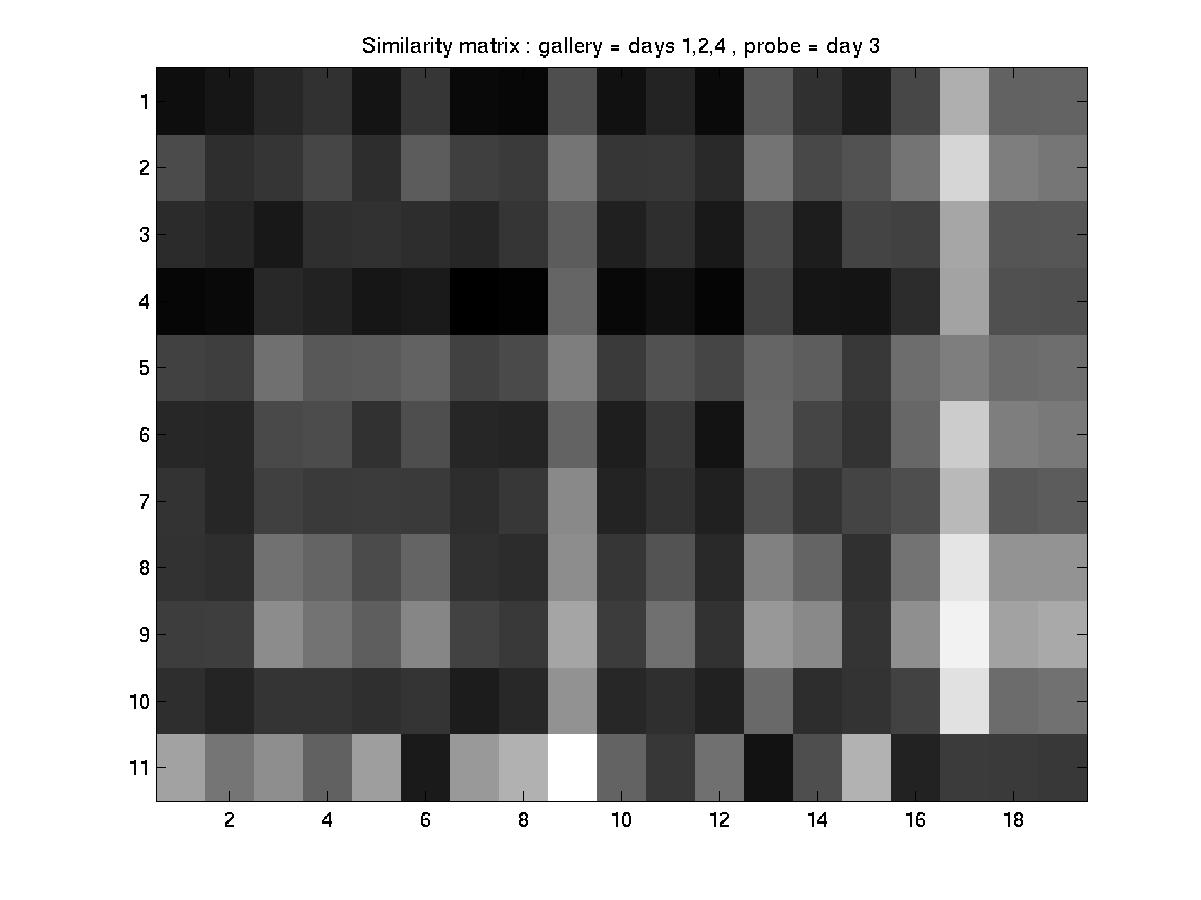
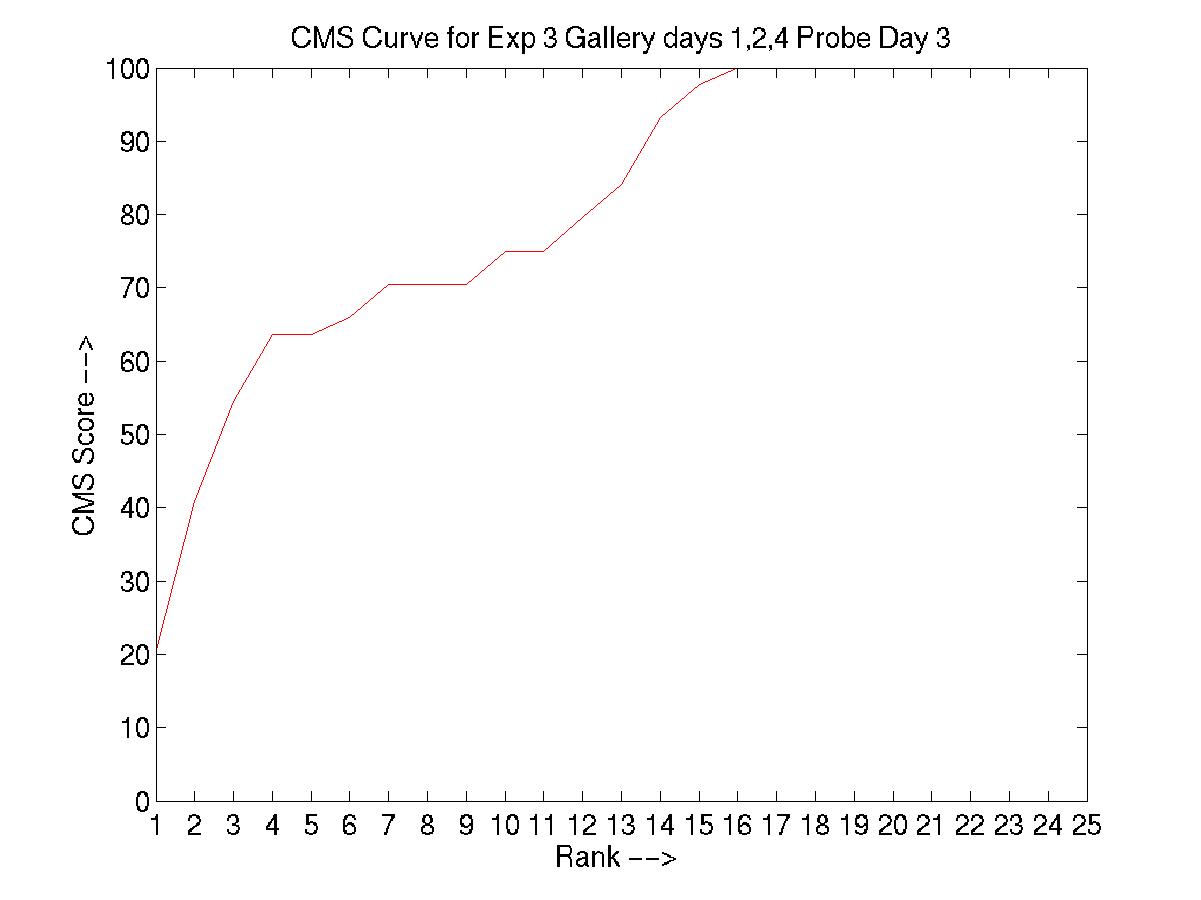
C. Day 032201 vs. days 030101, 031601, and 051001
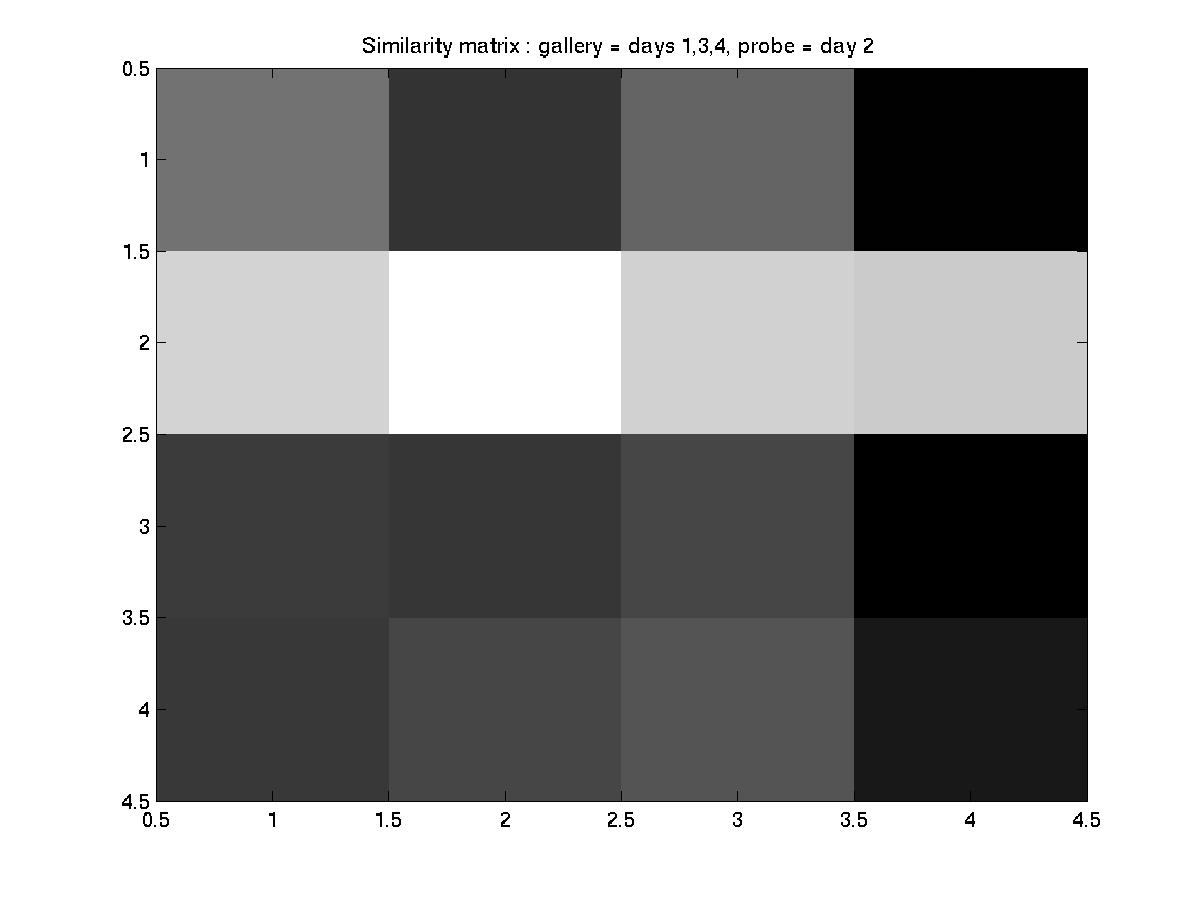
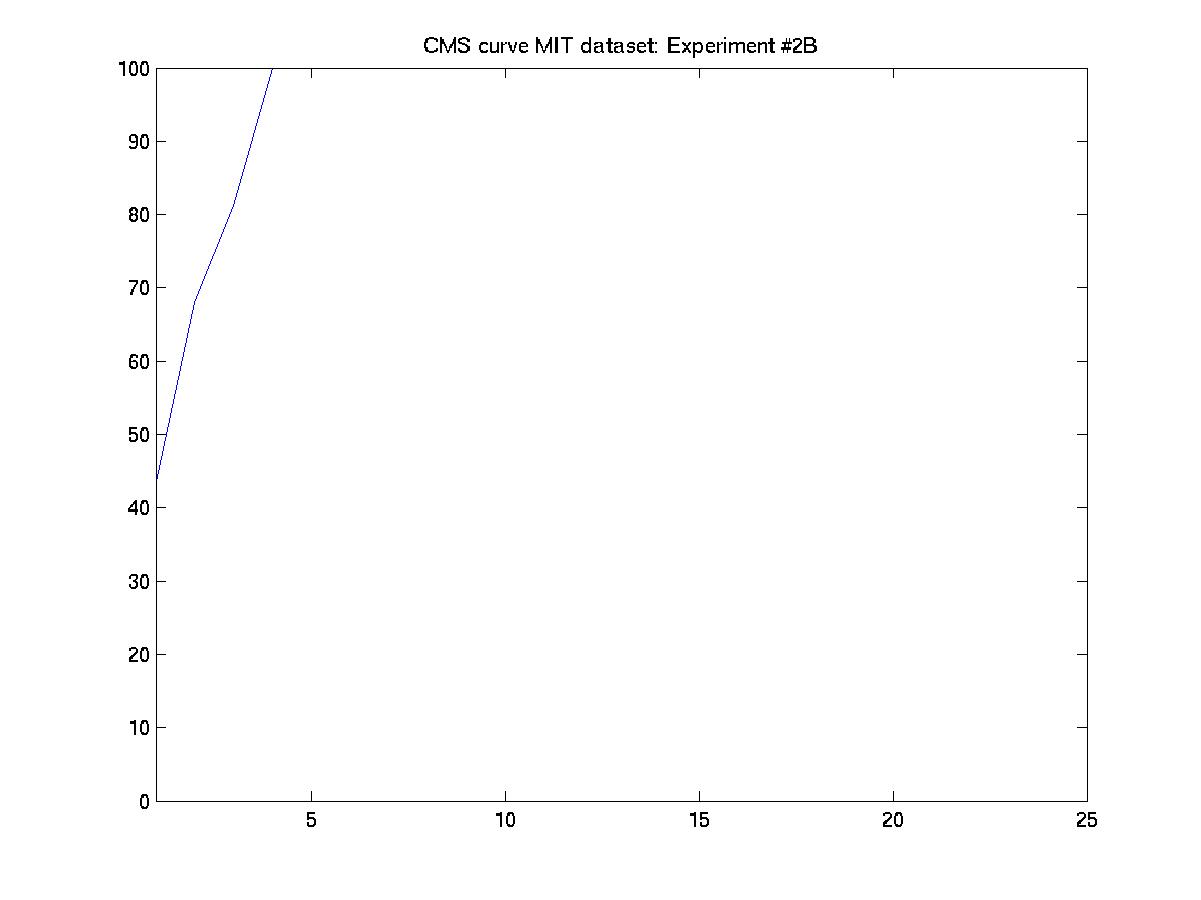
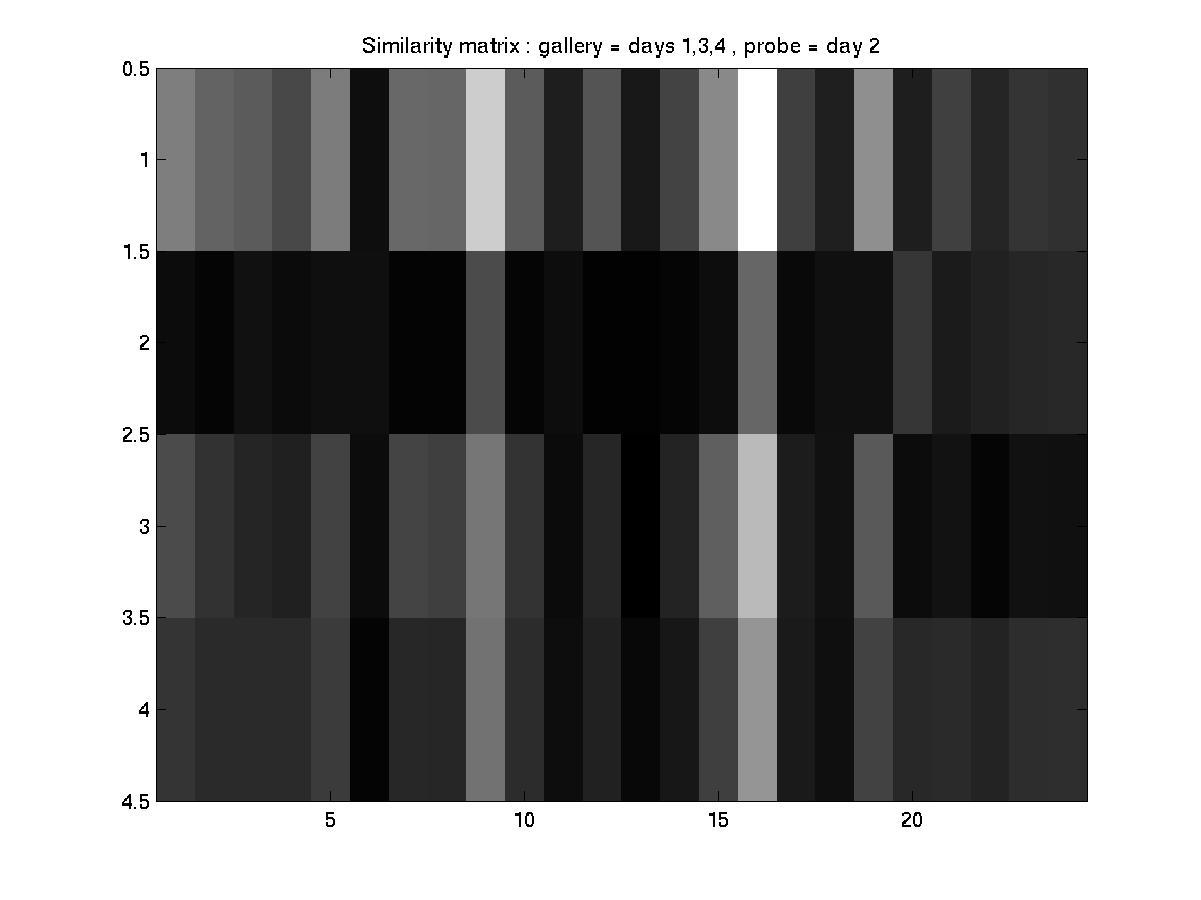
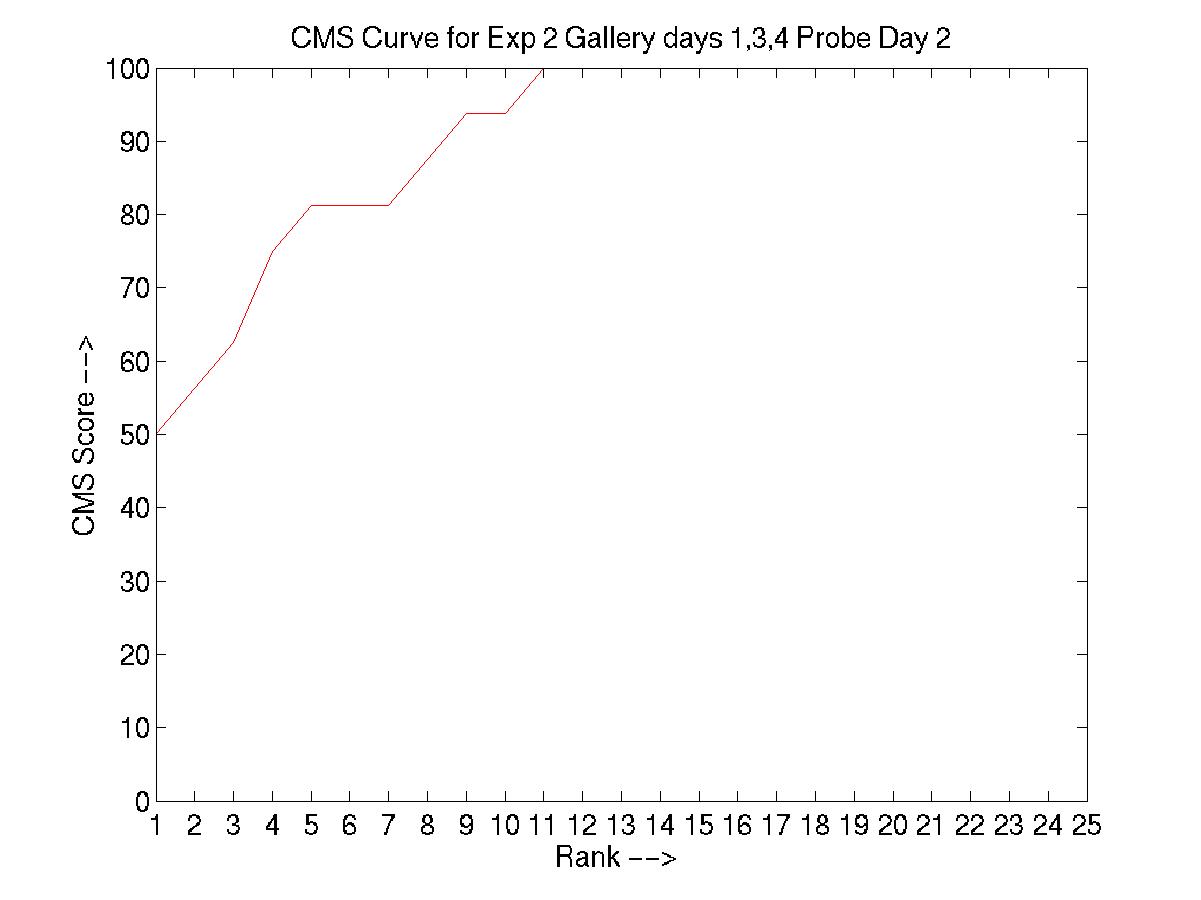
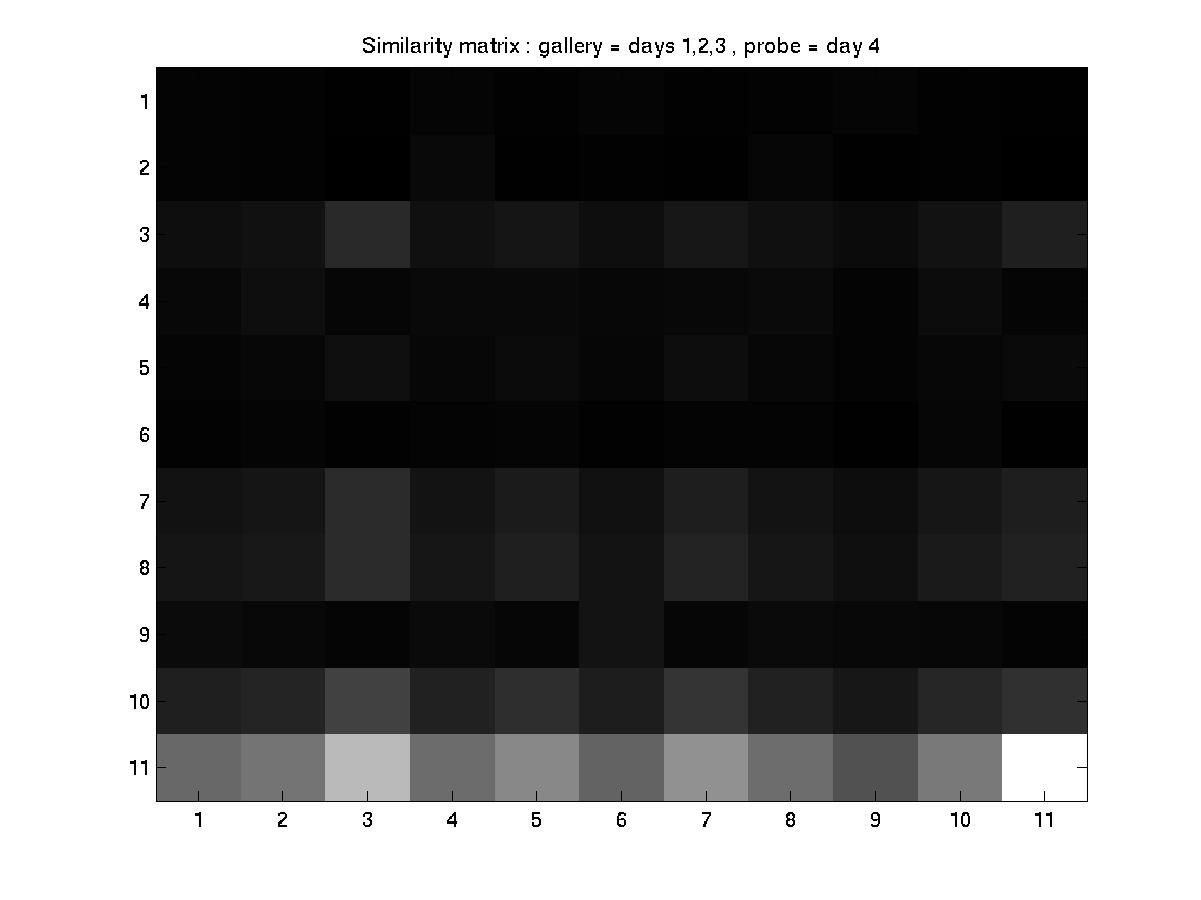
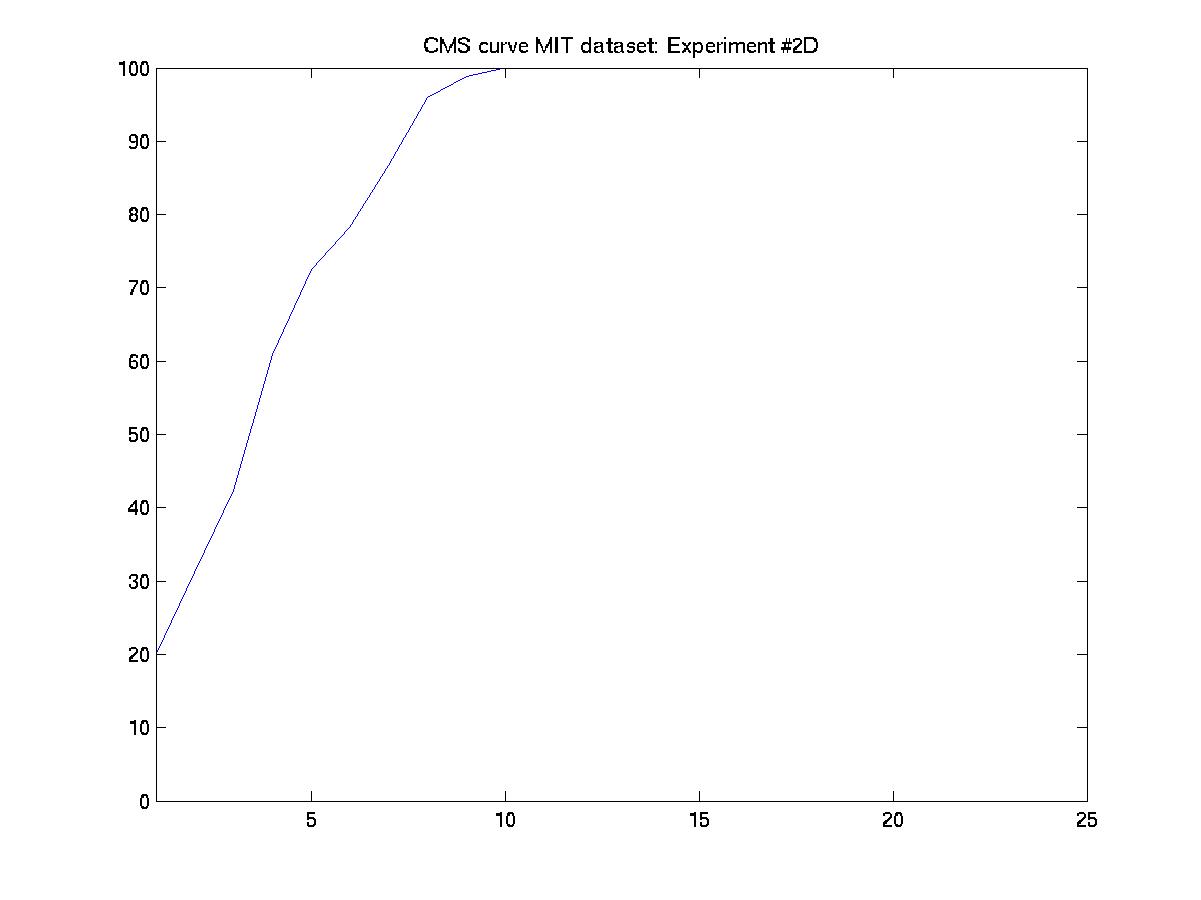
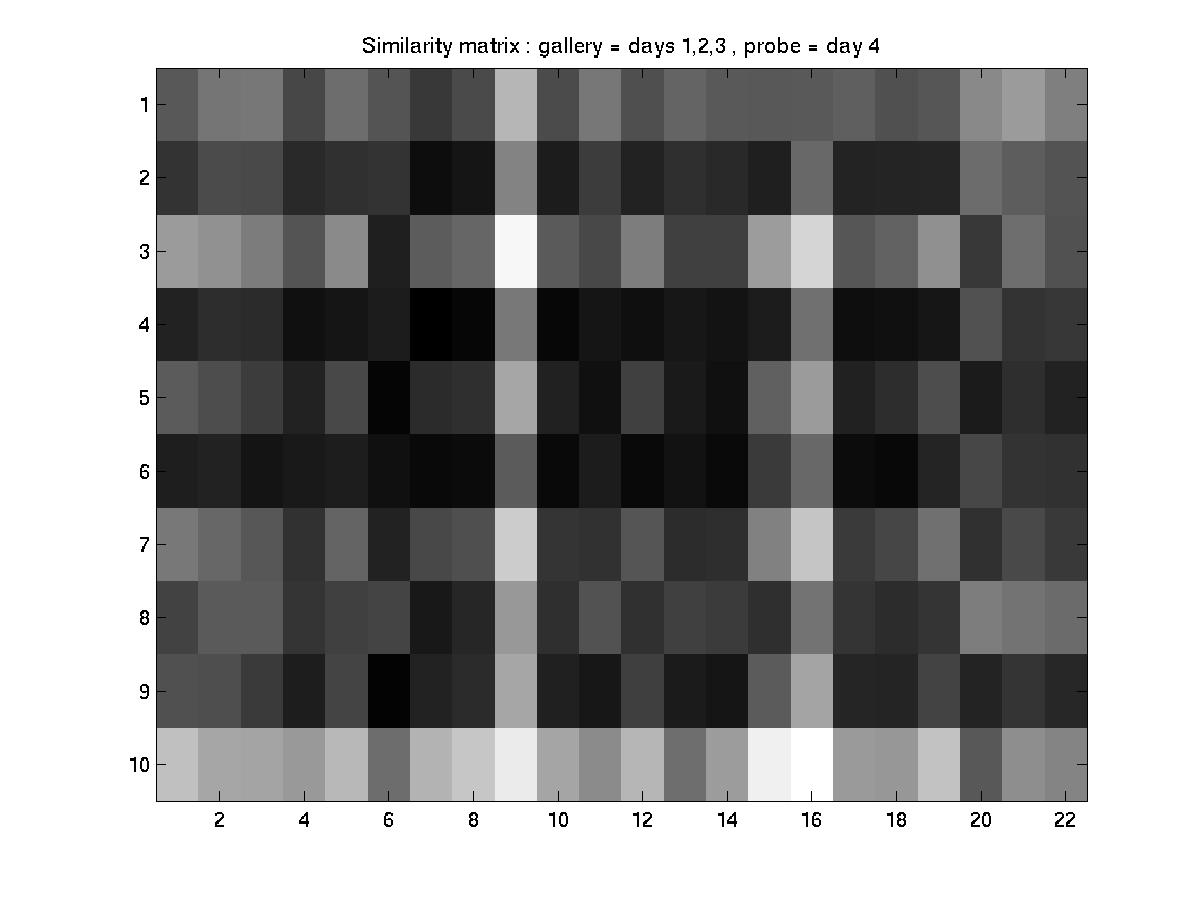
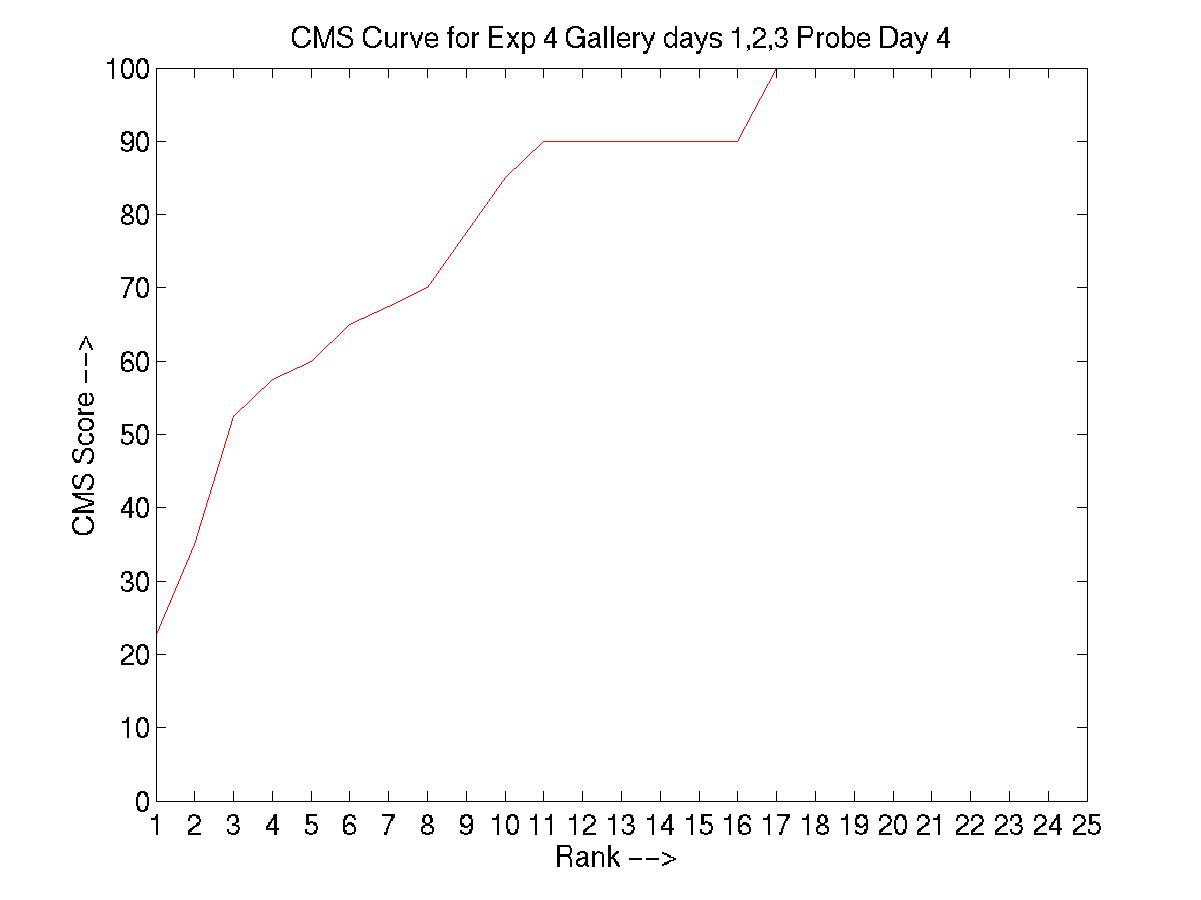
D. Day 051001 vs. days 030101, 031601, and 032201
A note on the results using HMM approach
An element essential to our training/testing philosophy is the HMM
model that we build for every subject in the database. With every
additional labeled incoming sequence during training, we update the model
for that particular subject. Therefore, the number of models built at the
end of a training procedure is equal to the of subjects present in that
particular experiment. To find a common ground between the experiments
designed by MIT and our algorithm, we have reorganized the MIT dataset as
follows:
MIT convention: day --> sequence
Modified convention: day --> subject --> sequences of the subject
And performed the experiments as designed by MIT (training with data
from 3 days and testing with the 4th).
Site First Created: 8/3/01 | Last Modified: 04/11/2002 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}